MALRec - Another Anime Recommendation System

Contents
- Introduction
- Web Scraping
- Data Exploration
- Recommendation System Implementation
- Deployment
- Final Thoughts
1. Introduction
This notebook showcases a recommendation system project that I have been working on, covering the end to end process of data collection to deployment of the web application. The purpose of this project is to create a recommendation system for users based on their preferences and viewing habits. Additionally, this model can account for multiple users and provide recommendations that it thinks the group can enjoy together. This project also gives me a chance to familiarize myself with technologies that I have not been utilizing as frequently.
A few other notebooks have also been uploaded onto this site and will be referenced to along this showcase, each notebook covers their own specific portions of the end to end journey.
2. Web Scraping
For reference, the following 3 notebooks cover most of my experimentation/implementation process for the web scraper:
- Part 1 - Focuses on gathering a reasonably wide range of content data from the site for analysis.
- Part 2 - Focuses on effectively gathering relevant user contributed data from the site.
- Part 3 - After completing data exploration of the data from Parts 1 and 2, improved upon the implementations to achieve over 90% reduction in time taken to scrape our data, and introduced an additional approach that can alleviate the problem of obscure titles not having enough user contributed data.
The most important component of any model is arguably the data. To properly round out the learning journey of this portfolio I decided to gather my data from scratch through web scraping a popular online anime database/community website MyAnimeList.
2.1 Content Data Approach
This is achieved by sending requests to the site and parsing the response we received using the BeautifulSoup package, identifying and saving the useful portions of the html content that was parsed. In our initial implementation, a list of top anime titles was scraped from the site, then detailed data (i.e. list of staff members, user reviews, etc.) was scraped from the detailed pages of each anime title.
However this approach was very inefficient as it means we need up to 6 requests per title, meaning that many hours was needed to go through approximately 13,000 of the most popular titles on the site.
After exploring the first round of scraped data I realised that most of the important content information can be found on a seasonal summary page on the website as shown below
In the improved implementation of the content web scraper, 1 request can gather data for an entire season’s worth of anime titles, cutting runtimes down by more then 90%. As a bonus, this approach gathers existing titles from the site that have their premiere dates listed returning more than twice the number of unique titles from our initial approach.
2.2 User Data Approach
As for user data, the initial approach periodically gathers a list of 20 recently active users from the site and scrapes their contributed anime title ratings data if available. This ensures that we are only targetting active users, and not inactive users who may have outdated or deactivated ratings list wasting our request attempt. Additionally, a public API provided by the site was used to scrape user ratings from each specific username we found.
The main limitation of this approach is that it introduces a recency bias to our user ratings data as it is less likely that these recently active users have watched and rated older titles in comparison to newer titles. Along with the nature of popular vs obscure titles we found that older/obscure titles were lacking in volume of user rating data collected.
To alleviate this problem I implemented an additional approach that allows us to scrape an anime title’s page to gather a list of 75 usernames per request, these usernames have recently interacted with that title in their own ratings list. This almost guarantees that when we scrape the users’ ratings list the title we require more data for will be included in all 75 lists (unless the user manage to remove the title from their list within the few seconds between our requests)
To identify titles that requires additional user ratings information I filtered for titles with an above average rating score, yet has appeared in less than 30 of the 20,000 user ratings lists scraped.
3. Data Exploration
For reference, the following notebook covers the data exploration from our initial dataset:
- Data Exploration - Exploratory data analysis on the content and user data gathered from our initial web scraper implementation.
3.1. Key Insights:
- A
1-10rating scale is provided on the site but overall users are mostly utilizing only the4-10scale, with the median/mean anime title being rated around6.5. This does not mean that all users are utilizing4-10scale, a significant portion of users are using1-10while another portion is using only7-10. - A title having a good rating score is correlated with being more popular
- Users are more likely to drop longer running titles halfway.
- Score distribution from the gathered user ratings data is not representative of the site’s score distribution.
3.2. Key Takeaways:
- User rating scores should be normalized when generating personal recommendations to properly recognise where a particular title stand on the user’s own rating scale.
- Popular/Highly rated titles are generally safe bets when recommending a title
- Standard 13 episode titles may be a safe bet, but the model can also look at a user’s existing ratings to determine whether a particular user has any preference for a title’s length (i.e. a movie vs 13 episodes vs 50+ episodes)
- This is expected due to a title’s score and popularity being correlated -> Higher rated titles will appear on user ratings more often with a higher average score compared to lower rated titles in general. This would not negatively impact our recommendations as I assume users would be more likely to enjoy higher rated titles.
4. Recommendation System Implementation
For reference, the following notebook covers the exploration and implementation of the recommendation system:
- Recommendation System Approaches - Explores and evaluates 3 different approaches to a recommendation system on our dataset.
4.1 Approaches
The following 3 approaches were explored, along with a baseline model for comparison:
-
Baseline Model - Simply provide ranked recommendations from the most popular titles that the user has not watched.
- Pros: Simple to implement and very quick to compute.
- Cons: Not all users will enjoy the most popular titles, recommendations are not really personalised
-
Content Based Filtering - Ranks title recommendations based on their contents’ cosine similarity with the titles found on the user’s ratings list.
- Pros: Recommendations will be similar to the titles that a user have watched (i.e. a user who mainly watches sports anime will most likely get recommendations for sports anime)
- Cons: Recommendations will not be diverse as the metric for similarity is based on how “close” the content of the titles are.
-
Collaborative Filtering - Ranks title recommendations based on what other users who have similar preferences enjoy, this is achieved by factorizing our user ratings list and applying a dot product between the feature vectors of our input user(s) and the anime titles. The output will be a similarity measure that suggests which titles are likely to be highly rated by the input user(s), based on existing data from the other users’ ratings.
- Pros: More diversity in the recommendations based on the experience of other existing users, Title A that may seem completely unrelated to Title B may be recommended because a user enjoyed Title B, and existing users who have enjoyed Title B seem to enjoy Title A as well.
- Cons: Assumes that users with seemingly similar ratings lists will enjoy the same titles. Not as effective for users with very few or no watched title
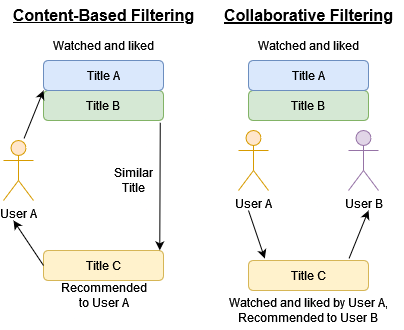
-
Hybrid - Combines both the Content Based and Collaborative approaches above. For simplicity’s sake I have placed an equal weightage to each of their normalized similarity measures.
- Pros: Combines the approaches to provide diversity in the recommendations, while still including titles with content similar to what the user already likes.
- Cons: Longer computational times as both approaches will need to be calculated.
4.2 Evaluation
The following 2 metrics are used for evaluation:
-
Mean Reciprocal Rank:
$ MRR = \dfrac{1}{N}\sum_{n=1}^N \dfrac{1}{rank_i} $
Where N is the total number of users, n is the nth user, i is the position of the first relevant item found within the recommendations
-
Normalized Discounted Cumulative Gain:
$ NDCG@K = \dfrac{DCG@K}{IdealDCG@K} $
$ DCG@K = \sum_{k=1}^K \dfrac{rel_k}{log_2 (k+1)} $
Where K is the total number of top recommendations we are evaluating, k is the kth highest predicted recommendation, rel_k is the relevance score of the recommendation at position k
IdealDCG@K is calculated by sorted the recommendations@K from order of highest relevance to lowest relevance before calculating the DGC@K. This will return the maximum achieveable DCG for the same set of ranked recommendations@K.
We will evaluate the recommendation system by simulating user interaction with the system as follows:
- The evaluated user will have a portion of their ratings list randomly sampled to be used as input data.
- Remaining part of the user’s rating list will be used to validate recommendations, simulating what other titles the user will watch after they have watched the input data.
- Recommendation system takes in input data and returns a set of 10 ranked recommendations.
- MRR/NDCG will be calculated from these recommendations and the validation data.
- This process is repeated for a sample of 1000 users to obtain sizeable samples of our evaluation metrics.
The results of the final evaluation are shown below, where both MRR and NDCG were evaluated with recommendations up to Rank-10:
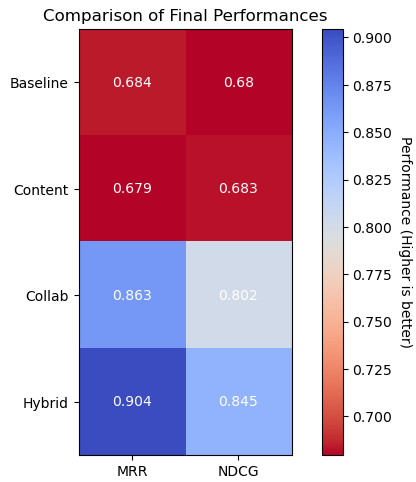
We notice that the content-based approach performed similarly to our baseline approach. However, the collaborative and hybrid approaches scored significantly higher in comparison.
Something of note is that on its own the content-based approach did not provide any value over our baselines in terms of recommendation performance. When combined with the collaborative approach however, it provided significant improvements to the recommendations made from the model where we see an MRR of 0.863 for collaborative approach jumping to 0.904 for hybrid approach, and NDCG of 0.802 jumping to 0.845.
5. Deployment
For reference, files required for deployment have been uploaded to the following repository, including the Dockerfile and corresponding environments.yml / requirements.txt:
For deployment a web application was built using Flask on python and deployed on a Docker container.
Below we see a demo of the recommendation system using the found of the website, username “Xinil”
5.1 Features
Using the components that we have already implemented in the previous sections, additional features were built into the web application such as the following:
- Able to extract user ratings list(s) from the input username(s) provided.
- Computes and generates output recommendations based on all of the titles that were found in the input. If multiple usernames were provided the recommendations will contain only titles that nobody has watched before to facilitate watch parties.
- Quickly access a title’s corresponding MAL webpage.
- Filter for recommendations for chosen Genres.
- Function to easily scrape and update content + collaborative datasets with new seasons of anime titles.
- In a production environment this function can be scheduled to execute every quarter and the dataset will be kept up to date, allowing recommendations for the latest titles.
5.2 Working Principles
As for how the web application works behind the scene, an object of a user defined class HybridRecommender stores both the datasets (as pandas DataFrames) and the logic behind the two other recommendation approaches.
When an input is sent, the user ratings list(s) are scraped and fed into the HybridRecommender for further processing and recommendation calculation.
The ranked recommendations are then routed and displayed on the front-end through flask and some predefined html templates, displaying our recommendations in a consistently formatted card that is what most users will be familiar with based on modern streaming/database services.
When the user filters the recommendations by Genre the same filter is applied on the ranked recommendations pandas DataFrame and rendered in the browser.
6. Final Thoughts
Throughout the course of this project, I had the opportunity to immerse myself in various aspects of software development. By utilizing Docker for deployment, I gained valuable experience in managing containerized environments and ensuring seamless application distribution. This skillset not only enabled me to deploy my projects efficiently but also provided an understanding of how to manage dependencies and maintain consistency across different systems.
The end-to-end nature of this project allowed me to appreciate the significance of design decisions and optimizations. Through careful consideration and implementation, I was able to create a more efficient and effective application. The experience working on this project has not only expanded my skillset but also provided valuable insights into best practices for future endeavors.
Overall, this project has been a fantastic opportunity to grow my skills and knowledge necessary in the field.