Anime webscraping - Part 3

Contents
1. Introduction
In previous notebooks we have explored scraping a popular anime database/community MyAnimeList for content and user rating information. After some EDA and exploration of Recommendation Systems using the scraped data I have thought of ways to improve our approach to how the data is scraped.
Limitations of the previous implementation that we want to address here:
- Long run times due to multiple requests required for each Title in serial
- Sampling a small subset of random active users do not return enough rating data for less popular Titles.
Proposed solutions to the above:
- Make requests in parallel, reduce number of requests required per Title by 3 orders of magnitude. Achieved by scraping areas of the website listing information for entire seasons of Titles within a single webpage, instead of scraping multiple subpages for each Title that was done prior.
- Identify Titles that we want more ratings data for, and from the Title’s subpage we directly scrape users that have recent interactions with the Title.
In this notebook I will walk through the implementation of the improved approach, the goal being to improve scraping performance and the quality of information that the scripts are returning. This new implementation will also allow us to easily update our anime content/user ratings datasets that are being used by the recommendation system, quickly keeping it up-to-date whenever a new season of titles is released.
2. Seasonal Title Scraping
import os
from bs4 import BeautifulSoup
import requests
import time
import pandas as pd
import random
import re
import csv
from multiprocessing.pool import ThreadPool as Pool
import logging
import tqdm
# Get request from site
site_url = 'https://myanimelist.net'
top_anime_url = site_url + '/anime/season/'
response = requests.get(top_anime_url + '2023/winter')
response.status_code
200
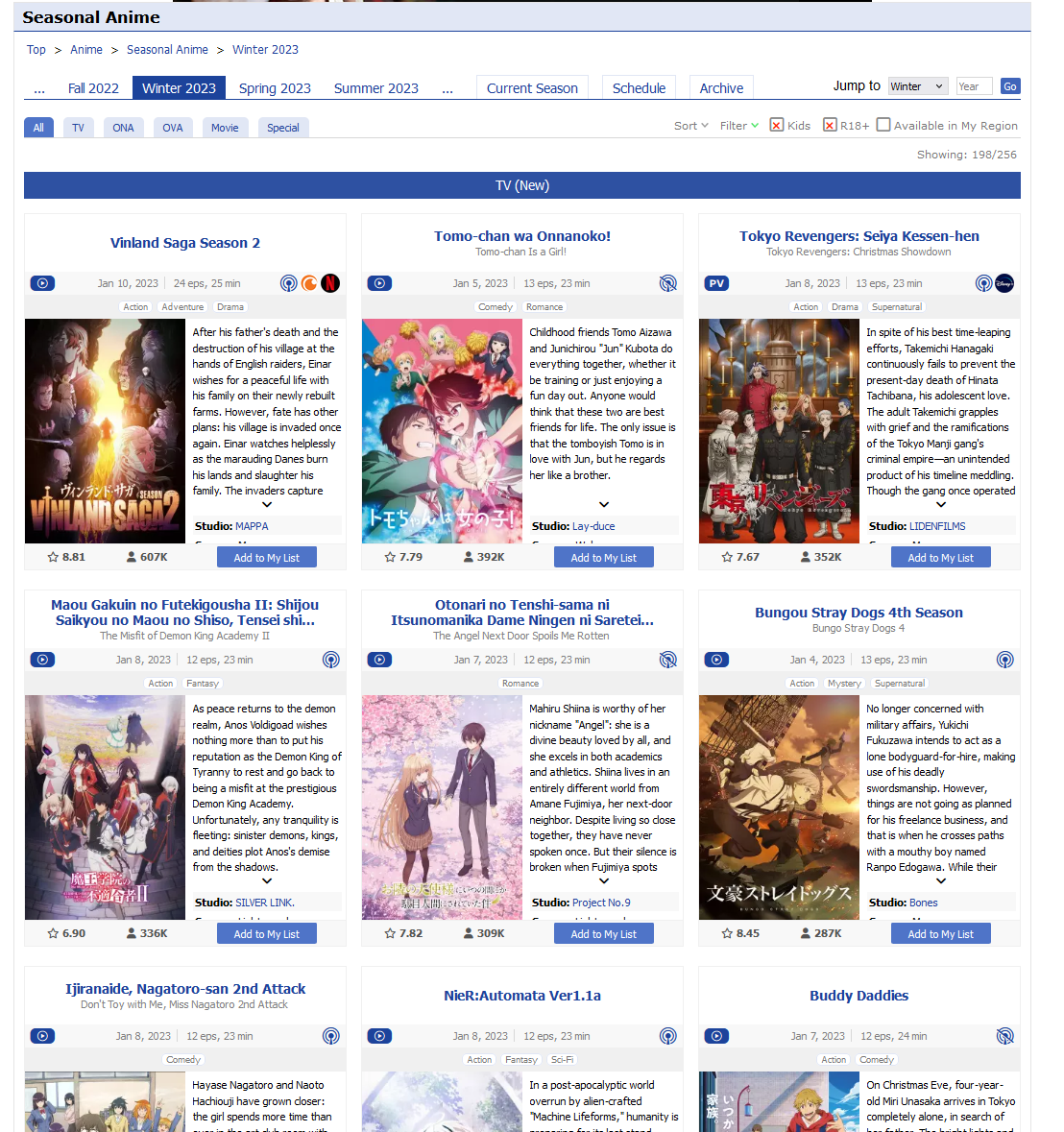
The above webpage contains summary information of all the anime titles that were released during the season, allowing us to scrape relevant data from a large number of titles with a single request, in constrast sending at least one request for each title.
# Extract html information from the webpage
doc = BeautifulSoup(response.text)
# Extract relevant portion of the webpage
#row_contents = doc.find_all('div', {'class':'js-anime-category-producer'})
type_contents = doc.find_all('div', {'class':'seasonal-anime-list'})
len(type_contents)
6
total = 0
for i in range(len(type_contents)):
print('Media Type :', type_contents[i].find('div', {'class':'anime-header'}).text)
print('Number of Titles: ', len(type_contents[i].find_all('div', {'class':'js-anime-category-producer'})))
total += len(type_contents[i].find_all('div',{'class':'js-anime-category-producer'}))
print(f'Total Number of Titles This Season: {total}')
Media Type : TV (New)
Number of Titles: 62
Media Type : TV (Continuing)
Number of Titles: 64
Media Type : ONA
Number of Titles: 83
Media Type : OVA
Number of Titles: 11
Media Type : Movie
Number of Titles: 25
Media Type : Special
Number of Titles: 11
Total Number of Titles This Season: 256
In the above webpage for 2023 Winter season there are 6 different media types with a total of 256 titles in the single response we received.
row_contents = type_contents[0].find_all('div', {'class':'js-anime-category-producer'})
# Starting Date, Number of Episodes, Episode Duration
[x.replace(' ','') for x in row_contents[0].find('div', {'class':'prodsrc'}).text.split('\n') if x.replace(' ','') != '']
['Jan10,2023', '24eps,', '25min']
# Genre
[x.text.strip() for x in row_contents[0].findAll('span', {'class': 'genre'})]
['Action', 'Adventure', 'Drama']
# Process Number of Episodes and Episode Duration into their own dictionary
def process_prodsrc(row_content):
content = [x.replace(' ','') for x in row_content.find('div', {'class':'prodsrc'}).text.split('\n') if x.replace(' ','') != '']
content_dict = {'Episodes':0,'Duration':0}
for c in content:
if ('ep' in c or 'eps' in c) and 'Sep' not in c:
content_dict['Episodes'] = c.replace('eps', '').replace('ep','').replace(',','')
elif 'min' in c:
content_dict['Duration'] = c.replace('min', '')
return content_dict
# Studio, Source, Themes, Demographic
[x for x in row_contents[0].find('div', {'class':'properties'}).text.split('\n') if x != '']
['StudioMAPPA', 'SourceManga', 'ThemesGoreHistorical', 'DemographicSeinen']
# Process Studio, Source, Themes, Demographic into their own dictionary
def process_properties(row_content):
content = [x for x in row_content.find('div', {'class':'properties'}).text.split('\n') if x != '']
content_dict = {'Studio':'', 'Source': '', 'Theme': '', 'Demographic': ''}
for c in content:
for k in content_dict.keys():
if k in c:
content_dict[k] = c.replace(k, '')
return content_dict
# Clean Synopsis text
def clean_text(text):
text = text.replace('\t','').replace('\n',' ').replace('\r',' ')
text = re.sub(' +', ' ',text).rstrip('\\').strip()
return text
# Cleaned Synopsis
clean_text(row_contents[0].find('div', {'class':'synopsis'}).text)
"After his father's death and the destruction of his village at the hands of English raiders, Einar wishes for a peaceful life with his family on their newly rebuilt farms. However, fate has other plans: his village is invaded once again. Einar watches helplessly as the marauding Danes burn his lands and slaughter his family. The invaders capture Einar and take him back to Denmark as a slave. Einar clings to his mother's final words to survive. He is purchased by Ketil, a kind slave owner and landlord who promises that Einar can regain his freedom in return for working in the fields. Soon, Einar encounters his new partner in farm cultivation—Thorfinn, a dejected and melancholic slave. As Einar and Thorfinn work together toward their freedom, they are haunted by both sins of the past and the ploys of the present. Yet they carry on, grasping for a glimmer of hope, redemption, and peace in a world that is nothing but unjust and unforgiving. [Written by MAL Rewrite] StudioMAPPA SourceManga ThemesGoreHistorical DemographicSeinen"
# Function to create a dictionary containing all the above information
def extract_info(row_contents, mediatype=''):
seasonal_contents = []
for i in range(len(row_contents)):
prodsrc = process_prodsrc(row_contents[i])
properties = process_properties(row_contents[i])
id_ = row_contents[i].find('div', {'class':'genres'})
title_ = row_contents[i].find('span', {'class':'js-title'})
score_ = row_contents[i].find('span', {'class':'js-score'})
members_ = row_contents[i].find('span', {'class':'js-members'})
start_date_ = row_contents[i].find('span', {'class':'js-start_date'})
image_ = row_contents[i].find('img')
contents = {
'MAL_Id': id_.get('id', -1) if id_ else '',
'Title': title_.text if title_ else '',
'Image': image_.get('src','') or image_.get('data-src','') if image_ else '',
'Score': score_.text if score_ else '',
'Members': members_.text if members_ else '',
'Start_Date': start_date_.text if start_date_ else '',
'Episodes': prodsrc['Episodes'],
'Duration': prodsrc['Duration'],
'Genres': [x.text.strip() for x in row_contents[i].findAll('span', {'class': 'genre'})],
'Studio': properties['Studio'],
'Source': properties['Source'],
'Themes': re.findall('[A-Z][^A-Z]*', properties['Theme']),
'Demographic': re.findall('[A-Z][^A-Z]*', properties['Demographic']),
'Synopsis': clean_text(row_contents[i].find('div', {'class':'synopsis'}).text),
'Type': mediatype
}
seasonal_contents.append(contents)
return seasonal_contents
seasonal_anime = extract_info(row_contents, 'TV')
a = pd.DataFrame(seasonal_anime)
a.head()
| MAL_Id | Title | Image | Score | Members | Start_Date | Episodes | Duration | Genres | Studio | Source | Themes | Demographic | Synopsis | Type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 49387 | Vinland Saga Season 2 | https://cdn.myanimelist.net/images/anime/1170/... | 8.81 | 608171 | 20230110 | 24 | 25 | [Action, Adventure, Drama] | MAPPA | Manga | [Gore, Historical] | [Seinen] | After his father's death and the destruction o... | TV |
| 1 | 52305 | Tomo-chan wa Onnanoko! | https://cdn.myanimelist.net/images/anime/1444/... | 7.79 | 392520 | 20230105 | 13 | 23 | [Comedy, Romance] | Lay-duce | Web manga | [School] | [] | Childhood friends Tomo Aizawa and Junichirou "... | TV |
| 2 | 50608 | Tokyo Revengers: Seiya Kessen-hen | https://cdn.myanimelist.net/images/anime/1773/... | 7.67 | 352516 | 20230108 | 13 | 23 | [Action, Drama, Supernatural] | LIDENFILMS | Manga | [Delinquents, Time , Travel] | [Shounen] | In spite of his best time-leaping efforts, Tak... | TV |
| 3 | 48417 | Maou Gakuin no Futekigousha II: Shijou Saikyou... | https://cdn.myanimelist.net/images/anime/1369/... | 6.90 | 336011 | 20230108 | 12 | 23 | [Action, Fantasy] | SILVER LINK. | Light novel | [Mythology, Reincarnation, School] | [] | As peace returns to the demon realm, Anos Vold... | TV |
| 4 | 50739 | Otonari no Tenshi-sama ni Itsunomanika Dame Ni... | https://cdn.myanimelist.net/images/anime/1240/... | 7.82 | 309405 | 20230107 | 12 | 23 | [Romance] | Project No.9 | Light novel | [School] | [] | Mahiru Shiina is worthy of her nickname "Angel... | TV |
Our function appears to be working, collecting the relevant information into a dictionary that can be easily converted into a pandas DataFrame.
Next we will include a few useful functions that we will use when scraping all the Titles available on the website, including some logging functionalities to help us track and debug any issues that may occur during the process.
# Helper functions
### Implement randomized sleep time in between requests to reduce chance of being blocked from site
def sleep(t=3):
rand_t = random.random() * (t) +0.5
time.sleep(rand_t)
### Save our dictionary to a .csv file
def write_seasonal_csv(items, path):
written_id = set()
# Assign header names with handling of seasons with no new release in certain media types
for i in range(len(items)):
if items[i]:
headers = list(items[i][0].keys())
break
# In case no new titles released
if headers:
# Open the file in write mode
if not path in os.listdir():
with open(path, 'w', encoding='utf-8') as f:
# Return if there's nothing to write
if len(items) == 0:
return
# Write the headers in the first line
f.write('|'.join(headers) + '\n')
with open(path, 'a', encoding='utf-8') as f:
# Write one item per line
for i in range(len(items)):
for item in items[i]:
values = []
# Check if title has already been added to prevent duplicated entries, some shows span multiple seasons
if item.get('MAL_Id') in written_id:
continue
for header in headers:
values.append(str(item.get(header, "")).replace('|',''))
f.write('|'.join(values) + "\n")
written_id.add(item.get('Id'))
### Send request to website
def get_response(url):
# Try for up to 3 times per URL
for _ in range(3):
try:
sleep(3)
response = requests.get(url, headers=req_head)
# If response is good we return the BS object for further processing
if response.status_code == 200:
doc = BeautifulSoup(response.text)
row_contents = doc.find_all('div', {'class':'seasonal-anime-list'})
if row_contents is None:
logging.warning(f'row_contents is None for {url}')
print(f'----------- row_contents is None for {url} ------------')
return row_contents
# If response suggests we are rate limited, make this thread sleep for ~3 minutes before continuing on next loop
elif response.status_code == 429 or response.status_code == 405:
logging.warning(f'{response.status_code} for {url}')
print(f'----------- {response.status_code} occured for {url} ------------')
buffer_t = random.random() * (40) + 160
sleep(buffer_t)
continue
# Any other unexpected response
else:
logging.warning(f'{response.status_code} for {url}')
print(f'----------- {response.status_code} occured for {url} ------------')
sleep(5)
continue
# Any unexpected issues with sending request
except:
logging.error('Error trying to send request')
buffer_t = random.random() * (40) + 100
sleep(buffer_t)
continue
print("-----------------------------Error sending request-----------------------------")
print(time.asctime())
# Instantiate variables
start_year, end_year = 1917, 2024
seasons = ['winter','spring','summer','fall']
req_head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0',
'X-MAL-CLIENT-ID':'e09c24c7eb88c3f399d9bd1355b4e015'}
seasonal_anime_filename = 'seasonal_anime.csv'
logging.basicConfig(filename='seasonal.log', filemode='w', format='%(asctime)s - %(levelname)s - %(message)s')
# Scrape all URLs between start and end years for specified seasons,
# multiprocessing available, option to override with a specified list of url available as well
def scrape(file_name, start_year=1917, end_year=2024, seasons=['winter','spring','summer','fall'], req=req_head, nprocesses=4, url_list=None):
top_anime_url = 'https://myanimelist.net/anime/season/'
# If specific URLs are not provided, a list of URLs will be generated based on start/end years and seasons provided.
if not url_list:
url_list = [top_anime_url + str(year) + '/' + str(season) for year in range(start_year,end_year+1) for season in seasons]
anime_list = []
# nprocesses number of threads processing URL list in sequence parallelly
with Pool(processes=nprocesses) as pool:
for type_contents in tqdm.tqdm(pool.imap(get_response, url_list), total=len(url_list)):
if type_contents is None:
continue
for i in range(len(type_contents)):
row_contents = type_contents[i].find_all('div', {'class':'js-anime-category-producer'})
mediatype = type_contents[i].find('div', {'class':'anime-header'}).text
seasonal_contents = extract_info(row_contents, mediatype)
anime_list.append(seasonal_contents)
sleep(5) # a few seconds sleep before next request is sent to avoid rate limit by site
# Write scraped data to disk
write_seasonal_csv(anime_list, file_name)
return anime_list
a = scrape(seasonal_anime_filename, start_year = 1917, end_year = 2024)
21%|████████████████▋ | 89/432 [04:48<17:23, 3.04s/it]
----------- 405 occured for https://myanimelist.net/anime/season/2000/fall ------------
----------- 405 occured for https://myanimelist.net/anime/season/2001/spring ------------
----------- 405 occured for https://myanimelist.net/anime/season/2001/winter ------------
21%|████████████████▉ | 90/432 [04:52<19:47, 3.47s/it]
----------- 405 occured for https://myanimelist.net/anime/season/2001/summer ------------
22%|█████████████████▋ | 94/432 [05:04<15:54, 2.83s/it]
----------- 405 occured for https://myanimelist.net/anime/season/2001/spring ------------
100%|████████████████████████████████████████████████████████████████████████████████| 432/432 [22:52<00:00, 3.18s/it]
#write_seasonal_csv(a,seasonal_anime_filename)
The above operation scraped all seasonal pages available on the website in just 20 minutes, a significant improvement from the previous implementation which took multiple hours just to scrape a subset of Titles on the website.
In the output we see that we appear to have been rate limited once within the 20 minutes. As the implemented logic will retry the same request thrice and there are no errors that repeated for three times, I assume that all requests were successful. But as a sanity check we will investigate these errors.
# Collect logged failed urls
with open('seasonal.log') as f:
f = f.readlines()
failed_urls = []
pattern = r'https://myanimelist.net/anime/season/[ a-zA-Z0-9./]+/[ a-zA-Z0-9./]+'
for line in f:
url = re.findall(pattern, line)
if url:
failed_urls.append(url[0])
len(failed_urls)
5
# Remove duplicated urls
failed_urls = list(dict.fromkeys(failed_urls))
len(failed_urls)
4
4 unique URLs faced rate limiting errors during scraping, these are urls for 2001 and 2002 seasons
df = pd.read_csv('seasonal_anime.csv')
df.head()
| MAL_Id | Title | Image | Score | Members | Start_Date | Episodes | Duration | Genres | Studio | Source | Themes | Demographic | Synopsis | Type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23189 | Dekobou Shingachou: Meian no Shippai | https://cdn.myanimelist.net/images/qm_50.gif | 5.84 | 1544 | 19170200 | 1 | 5 | ['Comedy'] | Unknown | Original | [] | [] | A man first realizes he's born to be a samurai... | Movie |
| 1 | 17387 | Imokawa Mukuzo: Genkanban no Maki | https://cdn.myanimelist.net/images/qm_50.gif | 5.26 | 1133 | 19170100 | 1 | 8 | ['Comedy'] | Unknown | Original | [] | [] | The third professionally produced Japanese ani... | Movie |
| 2 | 6654 | Namakura Gatana | https://cdn.myanimelist.net/images/anime/1959/... | 5.50 | 9633 | 19170630 | 1 | 4 | ['Comedy'] | Unknown | Original | ['Samurai'] | [] | Namakura Gatana meaning "dull-edged sword " i... | Movie |
| 3 | 10742 | Saru to Kani no Gassen | https://cdn.myanimelist.net/images/anime/4/837... | 4.93 | 1146 | 19170520 | 1 | 6 | ['Drama'] | Unknown | Other | [] | [] | A monkey tricks a crab and steals his food. Mo... | Movie |
| 4 | 24575 | Yume no Jidousha | https://cdn.myanimelist.net/images/qm_50.gif | 5.62 | 623 | 19170500 | 1 | 0 | [] | Unknown | Original | ['Racing'] | [] | It is most likely a story about a great dream ... | Movie |
# impute missing days/months in start_date
def impute_day(date):
if str(date)[-2:] == '00':
date = str(date)[:-2] + '01'
if str(date)[4:-2] == '00':
date = str(date)[:4] + '01' + str(date)[-2:]
return date
df.Start_Date = df.Start_Date.apply(impute_day)
df.head()
| MAL_Id | Title | Image | Score | Members | Start_Date | Episodes | Duration | Genres | Studio | Source | Themes | Demographic | Synopsis | Type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 23189 | Dekobou Shingachou: Meian no Shippai | https://cdn.myanimelist.net/images/qm_50.gif | 5.84 | 1544 | 19170201 | 1 | 5 | ['Comedy'] | Unknown | Original | [] | [] | A man first realizes he's born to be a samurai... | Movie |
| 1 | 17387 | Imokawa Mukuzo: Genkanban no Maki | https://cdn.myanimelist.net/images/qm_50.gif | 5.26 | 1133 | 19170101 | 1 | 8 | ['Comedy'] | Unknown | Original | [] | [] | The third professionally produced Japanese ani... | Movie |
| 2 | 6654 | Namakura Gatana | https://cdn.myanimelist.net/images/anime/1959/... | 5.50 | 9633 | 19170630 | 1 | 4 | ['Comedy'] | Unknown | Original | ['Samurai'] | [] | Namakura Gatana meaning "dull-edged sword " i... | Movie |
| 3 | 10742 | Saru to Kani no Gassen | https://cdn.myanimelist.net/images/anime/4/837... | 4.93 | 1146 | 19170520 | 1 | 6 | ['Drama'] | Unknown | Other | [] | [] | A monkey tricks a crab and steals his food. Mo... | Movie |
| 4 | 24575 | Yume no Jidousha | https://cdn.myanimelist.net/images/qm_50.gif | 5.62 | 623 | 19170501 | 1 | 0 | [] | Unknown | Original | ['Racing'] | [] | It is most likely a story about a great dream ... | Movie |
df.Start_Date = pd.to_datetime(df.Start_Date, format='%Y%m%d')
df.shape
(28744, 15)
The Start_Date in the above dataframe has been imputed and converted to datetime format, now we can conduct our sanity checks on the years that produced the errors while scraping.
df[df.Start_Date.dt.year == 2001]['Start_Date'].dt.month.value_counts()
Start_Date
10 112
4 85
7 56
12 43
8 39
3 34
5 32
1 29
6 22
11 22
2 21
9 21
Name: count, dtype: int64
df[df.Start_Date.dt.year == 2002]['Start_Date'].dt.month.value_counts()
Start_Date
4 121
10 87
1 52
8 36
11 36
3 34
7 34
12 33
5 26
9 24
2 22
6 20
Name: count, dtype: int64
We see that both 2001 and 2002 have many number of titles released throughout each of the twelve months of the year, suggesting that all four seasons we successfully scraped for both years.
3. Active Users Scraping
Now we are going to explore selectively scraping active users that have rated a Title that we want to collect more ratings for. Together with the seasonal scraping from the previous section this will allow the option of quickly updating the capabilities of the Recommendation System to include the newest titles into consideration.
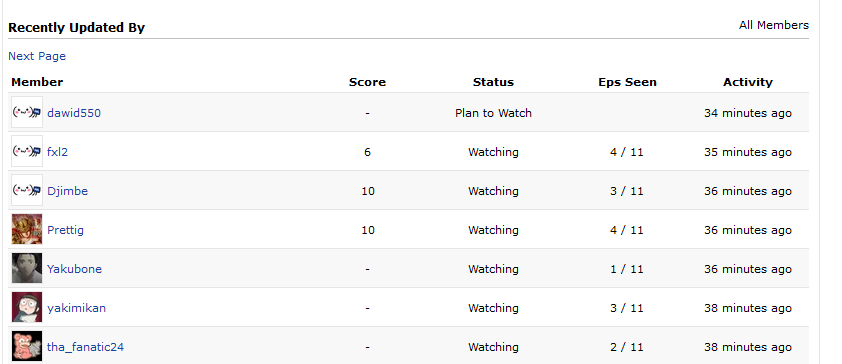
The below image shows a snippet of what this section looks like on the webpage.
response = requests.get('https://myanimelist.net/anime/49458/Kono_Subarashii_Sekai_ni_Shukufuku_wo_3/stats?show=0#members',headers=req_head)
doc = BeautifulSoup(response.text)
row_contents = doc.find_all('table', {'class':'table-recently-updated'})
# We expect to see Username , Score, Status, Eps Seen, Activity
[x.text for x in row_contents[0].findAll('tr')[1].findAll('td')]
['dawid550', '-', 'Plan to Watch', '', '36 minutes ago']
# Loop through found users and collect users that have rated the Title
res_list = []
for i in range(len(row_contents[0].findAll('tr'))):
res = [x.text for x in row_contents[0].findAll('tr')[i].findAll('td')]
if res[1] != '-':
res_list.append(res)
pd.DataFrame(res_list[1:], columns=res_list[0])
| Member | Score | Status | Eps Seen | Activity | |
|---|---|---|---|---|---|
| 0 | fxl2 | 6 | Watching | \n 4 / 11\n ... | 37 minutes ago |
| 1 | Djimbe | 10 | Watching | \n 3 / 11\n ... | 38 minutes ago |
| 2 | Prettig | 10 | Watching | \n 4 / 11\n ... | 38 minutes ago |
| 3 | CzechAnime | 10 | Watching | \n 5 / 11\n ... | 42 minutes ago |
| 4 | Fajar38 | 7 | Watching | \n 4 / 11\n ... | 42 minutes ago |
| 5 | Naitchu | 9 | Watching | \n 4 / 11\n ... | 43 minutes ago |
| 6 | MishMashMoshi | 7 | Watching | \n 4 / 11\n ... | 44 minutes ago |
| 7 | GriffonLord | 8 | Watching | \n 4 / 11\n ... | 45 minutes ago |
| 8 | Danderfluff | 7 | Watching | \n 5 / 11\n ... | 46 minutes ago |
| 9 | MrJast | 10 | Watching | \n 11 / 11\n ... | 46 minutes ago |
| 10 | kawaiigabz | 9 | Watching | \n 3 / 11\n ... | 48 minutes ago |
| 11 | boknight | 6 | Watching | \n 1 / 11\n ... | 49 minutes ago |
| 12 | fabian332 | 7 | Watching | \n 4 / 11\n ... | 50 minutes ago |
| 13 | mkody | 8 | Watching | \n 4 / 11\n ... | 50 minutes ago |
| 14 | Divyansenpai69 | 8 | Watching | \n 4 / 11\n ... | 50 minutes ago |
| 15 | human4ever | 7 | Watching | \n 2 / 11\n ... | 55 minutes ago |
| 16 | Travaughn13 | 10 | Watching | \n 4 / 11\n ... | 55 minutes ago |
| 17 | dnilos911 | 9 | Watching | \n 4 / 11\n ... | 58 minutes ago |
| 18 | LouLouLouLouLou | 10 | Watching | \n - / 11\n ... | 59 minutes ago |
| 19 | sorotomi97 | 8 | Watching | \n 3 / 11\n ... | 1 hour ago |
| 20 | mrbacon56 | 10 | Watching | \n 4 / 11\n ... | 1 hour ago |
| 21 | Plugma | 8 | Completed | \n 11 / 11\n ... | 1 hour ago |
| 22 | Kitto999 | 9 | Watching | \n 2 / 11\n ... | 1 hour ago |
| 23 | KeerthiVasanG | 8 | Watching | \n 5 / 11\n ... | 1 hour ago |
| 24 | LeviAck25 | 10 | Watching | \n 1 / 11\n ... | 1 hour ago |
| 25 | Koukyy | 8 | Watching | \n 2 / 11\n ... | 1 hour ago |
We see that out of 75 users in the response we have 25 users who have rated the title! From here we can reuse our previous user scraping script to obtain these users’ rating lists through the official API of the website so our system can use that information for collaborative filtering.
Should we require additional number of user ratings we can increment the number of members in the url to scrape additional pages of recent interactions. By design the webpage will return pages of 75 members and we have scraped the page starting at interaction number 0 to 74. In our scripts we can increment it by 75 each time until the desired number of usernames are obtained.
Next we can quickly go through the possible Titles that we need to obtain additional user ratings information from.
user_ratings = pd.read_csv('cleaned_user_ratings.csv')
user_ratings[user_ratings.Rating_Score != 0].Anime_Id.unique()
print(f'Number of unique titles scraped : {len(df)}')
print(f'Number of unique titles rated in our user dataset : {user_ratings[user_ratings.Rating_Score != 0].Anime_Id.nunique()}')
Number of unique titles scraped : 18062
Number of unique titles rated in our user dataset : 14914
user_ratings[~user_ratings['Anime_Id'].isin(df.Id)].sort_values('Rating_Score', ascending=False)
| Username | User_Id | Anime_Id | Anime_Title | Rating_Status | Rating_Score | Num_Epi_Watched | Is_Rewatching | Updated | Start_Date | |
|---|---|---|---|---|---|---|---|---|---|---|
| 4946590 | matti_god | 18193 | 57435 | Street Fighter 6 x Spy x Family Movie: Code: W... | completed | 10 | 1 | False | 2023-12-19 15:00:22+00:00 | 2023-12-04 |
| 3356659 | ShiroAlex | 12378 | 52745 | Liella no Uta 2 | completed | 10 | 12 | False | 2024-04-03 10:35:45+00:00 | NaN |
| 531240 | potatoxslayer | 1938 | 37954 | Neo-Aspect | completed | 10 | 1 | False | 2019-01-28 05:02:56+00:00 | NaN |
| 535345 | 45rfew | 1953 | 32807 | Xiong Chumo | completed | 10 | 104 | False | 2022-08-01 03:22:35+00:00 | NaN |
| 535348 | 45rfew | 1953 | 32818 | Xiong Chumo: Huanqiu Da Maoxian | completed | 10 | 104 | False | 2022-08-01 03:22:44+00:00 | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2143827 | SwopaKing | 7873 | 56906 | Isekai de Cheat Skill wo Te ni Shita Ore wa, G... | plan_to_watch | 0 | 0 | False | 2023-10-15 12:33:58+00:00 | NaN |
| 2143639 | M3m3supreme | 7872 | 49233 | Youjo Senki II | plan_to_watch | 0 | 0 | False | 2021-06-19 16:34:22+00:00 | NaN |
| 2143619 | M3m3supreme | 7872 | 34453 | Uma Musume: Pretty Derby PV | plan_to_watch | 0 | 0 | False | 2018-04-03 15:47:56+00:00 | NaN |
| 2143567 | M3m3supreme | 7872 | 53065 | Sono Bisque Doll wa Koi wo Suru (Zoku-hen) | plan_to_watch | 0 | 0 | False | 2022-09-18 10:22:21+00:00 | NaN |
| 5452183 | mintcakee | 20010 | 23057 | Yukidoke | plan_to_watch | 0 | 0 | False | 2023-10-23 10:12:55+00:00 | NaN |
93341 rows × 10 columns
print(f"Number of titles in user rating data that does not appear in scraped seasonal data : {user_ratings[~user_ratings['Anime_Id'].isin(df.Id)].Anime_Id.nunique()}")
Number of titles in user rating data that does not appear in scraped seasonal data : 3036
We see approximately 3000 titles appearing in our user ratings dataset, but they do no exist within our scraped aired titles. Upon further investigation it appears that these titles are scheduled to release in the further, or are promotional videos that do not fall under the category of a “proper show” and hence are excluded from the seasonal roster.
print(f'Number of titles within scraped seasonal data missing from user rating data : {len(df[~df.Id.isin(user_ratings[user_ratings.Rating_Score != 0].Anime_Id.unique())])}')
Number of titles within scraped seasonal data missing from user rating data : 5502
With more than 5000 titles it means an equivalent number of requests will be required to obtain the recent user interactions information. Extrapolating from the time required to scrape our seasonal data this would mean almost 4 hours to go through all 5000+ titles!
As an alternative we can ignore the really obscure Titles that also have low rating scores under the assumption that watchers would be less likely to enjoy them anyway. The likelihood of these titles getting recommended is also low as they would not rank high during collaborative filtering due to their low scores and low number of ratings.
df[(~df.Id.isin(user_ratings[user_ratings.Rating_Score != 0].Anime_Id.unique()))].describe()
| Id | Score | Members | Start_Date | Duration | |
|---|---|---|---|---|---|
| count | 5502.000000 | 5502.000000 | 5502.00000 | 5502 | 5502.000000 |
| mean | 33578.684842 | 2.237177 | 1041.49691 | 2008-09-22 08:29:50.185387008 | 24.303708 |
| min | 217.000000 | 0.000000 | 7.00000 | 1917-05-01 00:00:00 | 0.000000 |
| 25% | 18629.500000 | 0.000000 | 168.00000 | 2001-11-26 12:00:00 | 4.000000 |
| 50% | 36669.500000 | 0.000000 | 393.00000 | 2013-06-09 00:00:00 | 13.000000 |
| 75% | 48209.750000 | 5.670000 | 859.50000 | 2018-08-17 18:00:00 | 29.000000 |
| max | 58805.000000 | 7.970000 | 132342.00000 | 2024-12-01 00:00:00 | 167.000000 |
| std | 17495.517912 | 2.899072 | 3890.49838 | NaN | 27.931342 |
For demonstration purposes I would use 2000 members and a score of at least 6 as our filter.
df[(~df.Id.isin(user_ratings[user_ratings.Rating_Score != 0].Anime_Id.unique())) & (df.Members > 2000) & (df.Score >= 6)]
| Id | Title | Image | Score | Members | Start_Date | Episodes | Duration | Genre | Studio | Source | Themes | Demographic | Synopsis | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 133 | 4948 | Shounen Sarutobi Sasuke | https://cdn.myanimelist.net/images/anime/1266/... | 6.27 | 2238 | 1959-12-25 | 1 | 82 | ['Adventure' 'Fantasy'] | Toei Animation | Original | [] | [] | Magic Boy was the first ever Japanese animatio... |
| 149 | 2686 | Tetsujin 28-gou | https://cdn.myanimelist.net/images/anime/8/717... | 6.94 | 3872 | 1963-10-20 | 96 | 25 | ['Adventure' 'Sci-Fi'] | Eiken | Manga | ['Mecha'] | ['Shounen'] | Dr.Haneda was developing experimental giant ro... |
| 209 | 3900 | Ougon Bat | https://cdn.myanimelist.net/images/anime/2/286... | 6.88 | 2816 | 1967-04-01 | 52 | 25 | ['Action' 'Sci-Fi'] | sDai-Ichi DougaDongyang Animation | Novel | ['Super ' 'Power'] | [] | A golden warrior wearing a cape and a scepter ... |
| 229 | 5834 | Kyojin no Hoshi | https://cdn.myanimelist.net/images/anime/12/59... | 7.47 | 3206 | 1968-03-30 | 182 | 25 | ['Drama' 'Sports'] | TMS Entertainment | Manga | ['Team ' 'Sports'] | ['Shounen'] | The story is about Hyuma Hoshi a promising yo... |
| 238 | 5997 | Sabu to Ichi Torimono Hikae | https://cdn.myanimelist.net/images/anime/9/840... | 7.04 | 2748 | 1968-10-03 | 52 | 25 | ['Action' 'Adventure' 'Drama' 'Slice of Life'] | Toei Animation | Manga | ['Detective' 'Historical' 'Martial ' 'Arts'... | ['Shounen'] | The series follows the adventures of Sabu a y... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 17902 | 56840 | T.P BON | https://cdn.myanimelist.net/images/anime/1003/... | 6.95 | 3693 | 2024-05-02 | ? | 28 | ['Action' 'Adventure'] | Bones | Manga | ['Time ' 'Travel'] | [] | An ordinary high school student named Bon beco... |
| 17904 | 58689 | Yuanshen: Jinzhong Ge | https://cdn.myanimelist.net/images/anime/1229/... | 7.97 | 2176 | 2024-04-17 | 1 | 7 | ['Action' 'Drama' 'Fantasy'] | Unknown | Game | [] | [] | Animated short film about the backstory of the... |
| 17940 | 54866 | Blue Lock: Episode Nagi | https://cdn.myanimelist.net/images/anime/1239/... | 6.86 | 36190 | 2024-04-19 | 1 | 91 | ['Sports'] | 8bit | Manga | ['Team ' 'Sports'] | ['Shounen'] | A spin-off series of Blue Lock focusing on Sei... |
| 17946 | 57478 | Kuramerukagari | https://cdn.myanimelist.net/images/anime/1764/... | 6.33 | 5131 | 2024-04-12 | 1 | 61 | ['Mystery' 'Sci-Fi' 'Suspense'] | Team OneOne | Original | ['Detective'] | [] | This is a story that weaves together people an... |
| 17949 | 56553 | Kurayukaba | https://cdn.myanimelist.net/images/anime/1885/... | 6.48 | 4702 | 2024-04-12 | 1 | 63 | ['Mystery' 'Sci-Fi' 'Suspense'] | Team OneOne | Original | ['Detective'] | [] | Business is slow for the Ootsuji Detective Age... |
301 rows × 14 columns
Instantly we have cut the number of Titles we want to scrape down to 301, which will complete in less than 15 minutes.
With this, we can expect to collect enough information to add Titles from a new season to our recommendation system within 30 minutes! Approximately 200 requests (1 to obtain seasonal titles + recent user interactions from average of 150 titles released per season) which would take about 10 minutes, and an additional 20 minutes to obtain the user ratings data from the official API which is more lenient with its rate limiting in my experience.
4. Conclusion
In this notebook we have explore an improved implementation of our previous webscraping approach to obtaining content information and user ratings information from the website. This implementation cuts down the time taken to scrape our content information by over 90%, taking only 20 minutes to scrape the entire site now.
This targeted user approach improves the quality of user rating data that we will obtain. Previously we scraped user data indiscriminately as long as they are recently active, resulting in a lot of obscure titles missing from the dataset, and a lot of wasted API calls when the active user scraped does not maintain a useful rating list. The updated approach obtains the usernames directly from the Title’s recent interactions list, ensuring that the scraped user ratings data will at least contain information of the Title of interest.