Anime webscraping - Part 1

Contents
1. Introduction
In this notebook we will be scraping a popular anime database/community MyAnimeList, aiming to collect enough raw data from the anime titles available on the website for further processing and learning purposes.
The relevant python scripts and samples of the datasets can be found in the following repository.
import os
from bs4 import BeautifulSoup
import requests
import time
import pandas as pd
import random
import re
import csv
2. Title Scraping
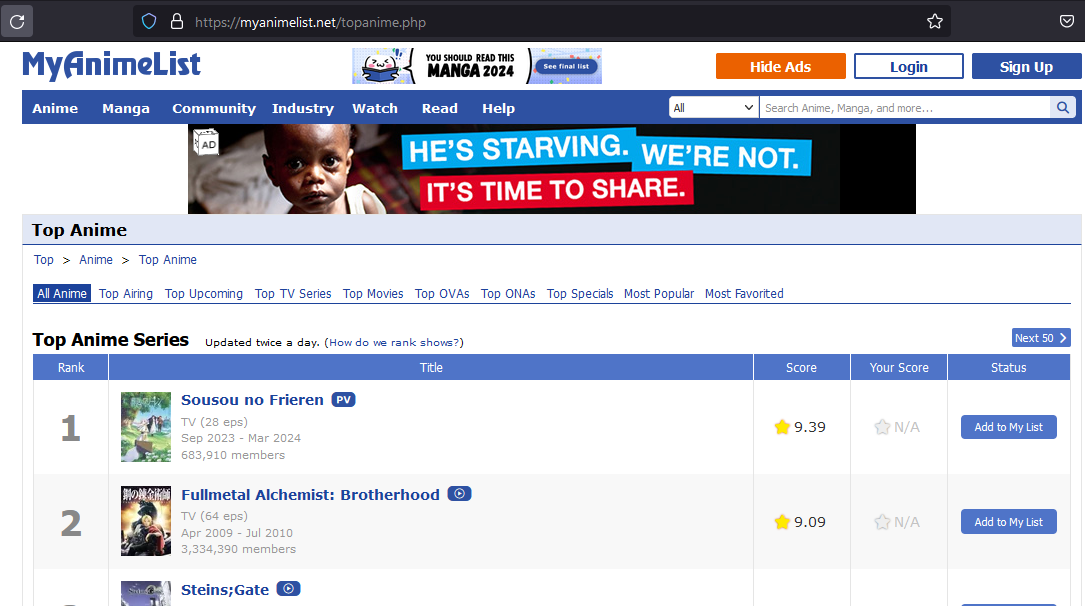
We will start by scraping high level information from anime titles that have been rated on the site. From the webpage we can guess what sort of information we can retrieve without accessing the detailed webpages for specific titles. As seen in the image below we will most likely be able to scrape Rank,Title,Score,Type,Airing Period,Members information.
# Get request from site
site_url = 'https://myanimelist.net'
top_anime_url = site_url + '/topanime.php?limit='
response = requests.get(top_anime_url + '0')
response.status_code
200
Above is a quick sanity check to show that we are able to get a desired response from our GET request to the topanime webpage.
# Extract html information from the webpage
doc = BeautifulSoup(response.text)
# Extract relevant portion of the webpage
row_contents = doc.find_all('tr', {'class':'ranking-list'})
row_contents[0]
<tr class="ranking-list">
<td class="rank ac" valign="top">
<span class="lightLink top-anime-rank-text rank1">1</span>
</td>
<td class="title al va-t word-break">
<a class="hoverinfo_trigger fl-l ml12 mr8" href="https://myanimelist.net/anime/52991/Sousou_no_Frieren" id="#area52991" rel="#info52991">
<img alt="Anime: Sousou no Frieren" border="0" class="lazyload" data-src="https://cdn.myanimelist.net/r/50x70/images/anime/1015/138006.jpg?s=09c2f2dec5891d8e8fbb9fa3b23c75b4" data-srcset="https://cdn.myanimelist.net/r/50x70/images/anime/1015/138006.jpg?s=09c2f2dec5891d8e8fbb9fa3b23c75b4 1x, https://cdn.myanimelist.net/r/100x140/images/anime/1015/138006.jpg?s=fdca2fe2777421f4c3aaa56a6ba8a46f 2x" height="70" width="50"/>
</a>
<div class="detail"><div id="area52991">
<div class="hoverinfo" id="info52991" rel="a52991"></div>
</div>
<div class="di-ib clearfix"><h3 class="fl-l fs14 fw-b anime_ranking_h3"><a class="hoverinfo_trigger" href="https://myanimelist.net/anime/52991/Sousou_no_Frieren" id="#area52991" rel="#info52991">Sousou no Frieren</a></h3><div class="icon-watch-pv2"><a class="mal-icon ml8 ga-click" href="https://myanimelist.net/anime/52991/Sousou_no_Frieren/video" title="Watch Promotional Video"><i class="malicon malicon-movie-pv"></i></a></div></div><br/><div class="information di-ib mt4">
TV (28 eps)<br/>
Sep 2023 - Mar 2024<br/>
683,910 members
</div></div>
</td>
<td class="score ac fs14"><div class="js-top-ranking-score-col di-ib al"><i class="icon-score-star fa-solid fa-star mr4 on"></i><span class="text on score-label score-9">9.39</span></div>
</td>
<td class="your-score ac fs14">
<div class="js-top-ranking-your-score-col di-ib al"> <a class="ga-impression" data-ga-click-type="data-ga-impression-type=" href="https://myanimelist.net/login.php?error=login_required&from=%2Ftopanime.php%3Flimit%3D0" onclick="dataLayer.push({'event':'ga-js-event','ga-js-event-type':''})"><i class="icon-score-star fa-solid fa-star mr4"></i><span class="text score-label score-na">N/A</span></a>
</div>
</td>
<td class="status ac"> <a class="js-form-user-status js-form-user-status-btn Lightbox_AddEdit btn-addEdit-large btn-anime-watch-status js-anime-watch-status notinmylist ga-impression" data-ga-click-type="anime_ranking" data-ga-impression-type="anime_ranking" href="https://myanimelist.net/ownlist/anime/add?selected_series_id=52991&hideLayout=1&click_type=anime_ranking" onclick="dataLayer.push({'event':'ga-js-event','ga-js-event-type':'anime_ranking'})">Add to My List</a></td>
</tr>
Using the BeautifulSoup4 package we are able to easily parse the response html, correctly identifying the portion of the response that contains the relevant information. In the above html sample we see the portion of the response that corresponds to the highest ranking title “Sousou no Frieren” on the website and the other information that we have predicted at the start of this notebook.
# Helper functions
### Implement randomized sleep time in between requests to reduce chance of being blocked from site
def sleep(3):
rand_t = random.random() * (t) + 0.5
time.sleep(rand_t)
print(f"Sleeping for {rand_t}s")
### Clean up extracted text information
def parse_episodes(content):
result = []
for i in content:
r = i.strip()
result.append(r)
return result
### Return only numeric characters from a string
def return_numeric(string):
try:
text = re.findall("\d+", string)[0]
except IndexError:
text = '?'
return text
### Save our dictionary to a .csv file
def write_csv(items, path):
# Open the file in write mode
with open(path, 'w', encoding='utf-8') as f:
# Return if there's nothing to write
if len(items) == 0:
return
# Write the headers in the first line
headers = list(items[0].keys())
f.write(','.join(headers) + '\n')
# Write one item per line
for item in items:
values = []
for header in headers:
values.append(str(item.get(header, "")).replace(',',' '))
f.write(','.join(values) + "\n")
Above are some helper self-explanatory functions that we will be using when scraping the website.
# Extract high level information from row_contents
def extract_info(top_anime, row_contents):
stop = False
for i in range(len(row_contents)):
episode = parse_episodes(row_contents[i].find('div', class_ = "information di-ib mt4").text.strip().split('\n'))
id_str = row_contents[i].find('td', class_='title al va-t word-break').find('a')['id']
ranking = {
'Id' : return_numeric(id_str),
'Rank' : row_contents[i].find('td', class_ = "rank ac").find('span').text,
'Title': row_contents[i].find('div', class_="di-ib clearfix").find('a').text,
'Rating': row_contents[i].find('td', class_="score ac fs14").find('span').text,
'Image_URL': row_contents[i].find('td', class_ ='title al va-t word-break').find('img')['data-src'],
'Type' : episode[0].split('(')[0].strip(),
'Episodes': return_numeric(episode[0].split('(')[1]),
'Dates': episode[1],
'Members': return_numeric(episode[2])
}
top_anime.append(ranking)
if ranking['Rating']=='N/A':
stop = True
return top_anime, stop
The above function helps to process the response html, storing each title’s information within a dictionary, and storing all the dictionaries in a list where they wait for their turn to be written to disk.
Information is parsed mainly with the help of BeautifulSoup, the previously seen helper functions are also used here when some of the parsed data may require additional cleaning before being added to the dictionary.
An early stopping criteria is also built into this function. As the webpage’s title scores are sorted in a descending order, it is reasonable to assume that titles missing a “Rating” score have not aired or are too obscure. The script will stop scraping when it detects the first title that does not contain a “Rating” score.
# Loop to scrape top anime pages, stop when non-rated title is found
def scrape_top_anime(file_name, t):
top_anime = []
stop = False
counts = 0
while not stop:
sleep(3)
response = requests.get(top_anime_url + str(counts))
print(f"Current counts: {counts}, Request Status: {response.status_code}")
while response.status_code != 200:
sleep()
response = requests.get(top_anime_url + str(counts))
doc = BeautifulSoup(response.text)
row_contents = doc.find_all('tr', {'class':'ranking-list'})
top_anime, stop = extract_info(top_anime, row_contents)
counts += 50
write_csv(top_anime, file_name)
The function contains the overall logic used when scraping the topanime section of the site, utilizing the functions from before to extract information before writing everything to disk.
df = pd.read_csv('top_anime_list.csv')
df
| Id | Rank | Title | Rating | Image_URL | Type | Episodes | Dates | Members | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 52991 | 1 | Sousou no Frieren | 9.39 | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 28 | Sep 2023 - Mar 2024 | 670 |
| 1 | 5114 | 2 | Fullmetal Alchemist: Brotherhood | 9.09 | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 64 | Apr 2009 - Jul 2010 | 3 |
| 2 | 9253 | 3 | Steins;Gate | 9.07 | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 24 | Apr 2011 - Sep 2011 | 2 |
| 3 | 28977 | 4 | Gintama° | 9.06 | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 51 | Apr 2015 - Mar 2016 | 628 |
| 4 | 38524 | 5 | Shingeki no Kyojin Season 3 Part 2 | 9.05 | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 10 | Apr 2019 - Jul 2019 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 13295 | 49369 | 13296 | Shinkai no Survival! | NaN | https://cdn.myanimelist.net/r/50x70/images/ani... | Movie | 1 | Aug 2021 - Aug 2021 | 382 |
| 13296 | 57798 | 13297 | Shinkalion: Change the World | NaN | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | ? | Apr 2024 - | 2 |
| 13297 | 38114 | 13298 | Shinkansen Henkei Robo Shinkalion The Animatio... | NaN | https://cdn.myanimelist.net/r/50x70/images/ani... | ONA | 1 | Aug 2018 - Aug 2018 | 457 |
| 13298 | 22313 | 13299 | Shinken Densetsu: Tight Road | NaN | https://cdn.myanimelist.net/r/50x70/images/ani... | TV | 13 | Oct 1994 - Dec 1994 | 738 |
| 13299 | 34697 | 13300 | Shinmai | NaN | https://cdn.myanimelist.net/r/50x70/images/ani... | Special | 4 | Apr 2008 - Apr 2008 | 234 |
13300 rows × 9 columns
df['Rating'].isna().sum()
16
For reference, the final file containing the scraped data is shown in the dataframe above. A total of 13300 titles were scraped, 16 of which contains missing “Rating” scores. This 16 titles were scraped as the script extracted data in batches of 50 titles.
3. Additional Information Scraping
The dataset obtained in the previous section provides some high level information across the many titles on the website. However, for further analysis and creation of recommendation systems we are interested in obtaining more detailed information of each title.
To achieve that, we can go beyond just the topanime section of the site, into the webpage of each title and their own subpages to extract even more information.
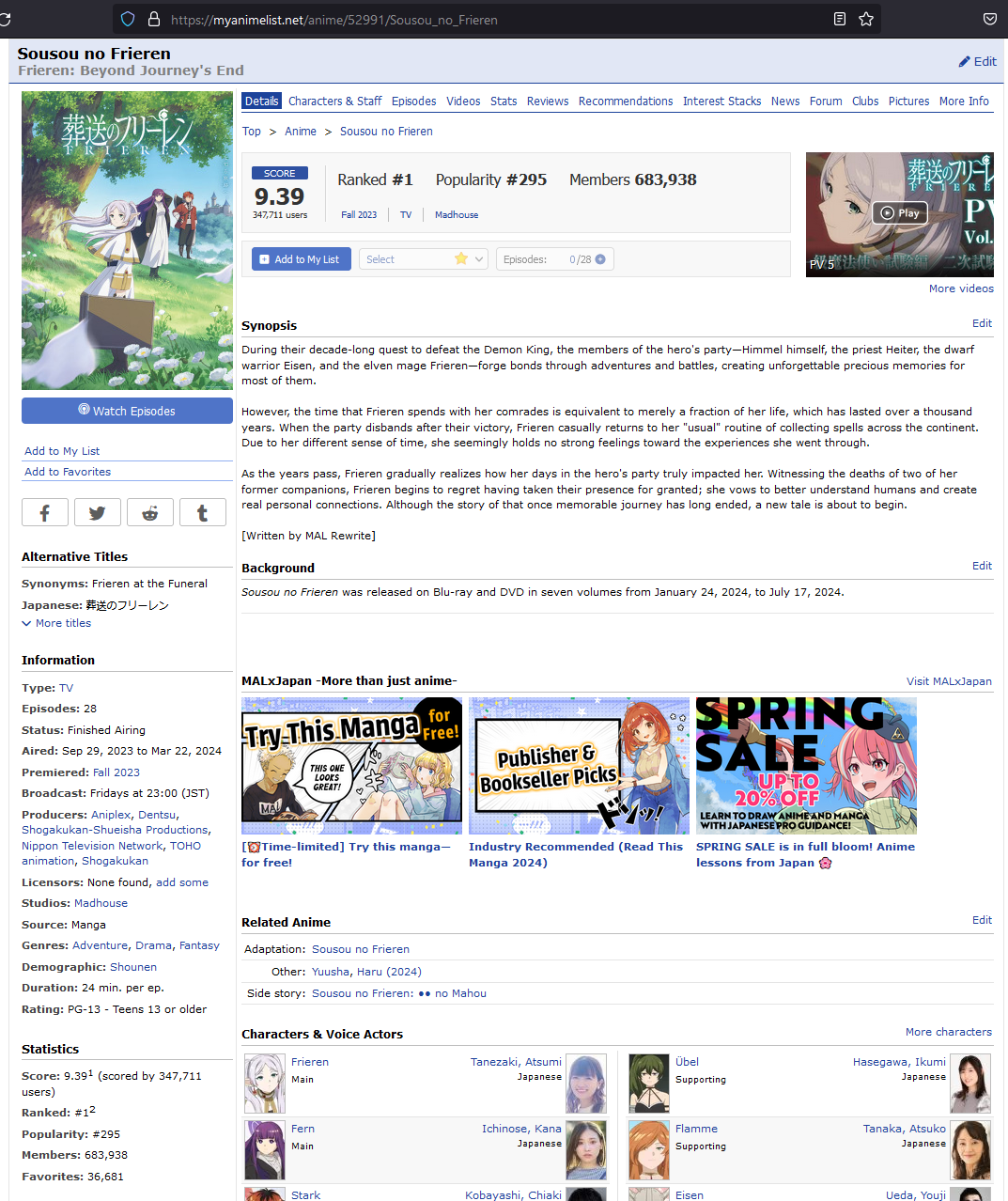
In the screenshot below we can see an abundance of information we can extract from the title’s webpage, towards the left there is a sidebar containing additional information and statistics of the title. At the top there are links to subpages that contains even more information of the title. Our goal in this section would be to identify and scrape relevant data to flesh out our dataset. We will do this for all 13300 titles found in the previous section
# Retrieve webpage url of specific pages for a title
def get_link_by_text(soup, anime_id, text):
urls = list(filter(lambda x: str(anime_id) in x["href"], soup.find_all("a", text=text)))
return urls[0]["href"]
The above function retrieve the url of specific subpages of the title, allowing us to send follow up requests and extract data from these subpages.
# Helper function to try get request; if fail 3 times log the title id in .csv file
def get_request(link, req_head, anime_id):
for _ in range(3):
try:
data = requests.get(link, headers=req_head)
if data.status_code !=200:
sleep()
continue
else:
return data
except:
buffer_t = random.random() * (40) + 100
time.sleep(buffer_t)
continue
print(f"Error with Title Id {anime_id}")
if not 'log_id.csv' in os.listdir():
with open('log_id.csv','w', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
headers = ['MAL_Id', 'URL']
writer.writerow([anime_id, link])
with open('log_id.csv','a', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
writer.writerow([anime_id, link])
The function above contains some logic to handle exceptions or error codes when sending our GET requests. If we suspect any rate limiting from the website’s end we will pause our requests for approximately 2 minutes to avoid getting banned. Should no proper response be received after 3 requests for the title we will log the title and subpage url into a .csv file for further investigation.
# Extract 1st page of reviews
def get_reviews(link, anime_id):
sleep()
review_link = f"{link}?p=1"
#data = requests.get(review_link, header=req_head)
data = get_request(review_link, req_head, anime_id)
if data is None:
return ['Error'],['Error']
soup = BeautifulSoup(data.text, "html.parser")
tags = soup.find_all("div", class_ = "tags")
reviews = soup.find_all("div", class_="text")
return tags, reviews
# Function to format reviews+tags
def get_review_tags(soup_tags, soup_reviews, anime_id):
extra_tags = ['Funny','Informative','Well-written','Creative','Preliminary']
review_tags = []
output = []
soup_reviews = [r.get_text() for r in soup_reviews]
for soup_tag in soup_tags:
curr_tags = []
tags = soup_tag.text
#tags = re.findall('[A-Z][^A-Z]*', tags)
if 'Not' in tags:
curr_tags.append("Not-Recommended")
elif "Mixed" in tags:
curr_tags.append("Mixed-Feelings")
else:
curr_tags.append("Recommended")
for tag in extra_tags:
if tag in tags:
curr_tags.append(tag)
review_tags.append(curr_tags)
rt = list(zip(soup_reviews, review_tags))
for row in rt:
r, t = row
output.append([anime_id, r, t])
return output
# Helper function to write review/tags to csv file
def write_new_reviews(file_name, l):
if not l:
return
if not file_name in os.listdir():
with open(file_name,'w', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
headers = ['MAL_Id','Review','Tags']
writer.writerow(headers)
with open(file_name,'a', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
for row in l:
writer.writerow(row)
The “Reviews” subpage requires some formatting/cleaning before writing the data to disk. The above functions were made to handle this subpage.
The first function retrieves the first page of reviews from the title, returning lists of all the reviews and their corresponding tags found, handling of titles with zero reviews is also done here. The next two functions processes the scraped data and write them to disk.
# Extract recommended anime title and number of recommendations
def get_recs(link_recommendations, anime_id):
sleep()
#data = requests.get(link_recomendations, header=req_head)
data = get_request(link_recommendations, req_head, anime_id)
if data is None:
return ['Error'],['Error']
soup = BeautifulSoup(data.text, "html.parser")
soup.script.decompose()
rec_ids = []
rec_counts = []
soup_ids = soup.find_all('div', {'class':'hoverinfo'})
soup_rec_counts = soup.find_all('a', {'class':'js-similar-recommendations-button'})
for i in range(len(soup_ids)):
rec_id = return_numeric(soup_ids[i]['rel'])
rec_ids.append(rec_id)
if i < len(soup_rec_counts):
rec_counts.append(soup_rec_counts[i].find('strong').text)
else:
rec_counts.append('1')
return rec_ids, rec_counts
Next, we have a function to scrape the “Recommendations” subpage, identifying the recommended titles and the number of recommendations they have received. Handling of missing data in the case where no other titles are recommended is also done here.
# Extract title details and statistics
def scrape_anime_info(link_stats, anime_id, anime_info):
# Get webpage
#data = requests.get(link_stats, header=req_head)
data = get_request(link_stats, req_head, anime_id)
if data is None:
return anime_info
soup = BeautifulSoup(data.text, "html.parser")
soup.script.decompose()
# Scrape and store information in dict
anime_info["MAL_Id"] = anime_id
anime_info["Name"] = soup.find("h1", {"class": "title-name h1_bold_none"}).text.strip()
score = soup.find("span", {"itemprop": "ratingValue"})
if score is None:
score = '?'
try:
anime_info['Score'] = score.text.strip()
except:
print('Empty Score')
anime_info['Genres'] = [x.text.strip() for x in soup.findAll("span", {"itemprop": "genre"})]
try:
anime_info['Demographic'] = anime_info['Genres'][-1]
except:
print('Empty Genre')
for s in soup.findAll("span", {"class": "dark_text"}):
info = [x.strip().replace(" ", " ") for x in s.parent.text.split(":")]
cat, v = info[0], ":".join(info[1:])
v.replace("\t", "")
if cat in ['Synonyms','Japanese','English']:
cat += '_Name'
v = v.replace(',', '')
anime_info[cat] = v
continue
if cat in ['Broadcast','Genres','Demographic','Score'] or cat not in anime_info.keys():
continue
elif cat in ['Producers','Licensors','Studios']:
v = [x.strip() for x in v.split(",")]
elif cat in ['Ranked','Popularity']:
v = v.replace('#',"")
v = v.replace(',', '')
elif cat in ['Members','Favorites','Watching','Completed','On-Hold','Dropped','Plan to Watch','Total']:
v = v.replace(',','')
anime_info[cat] = v
# Scrape scoring stats
for s in soup.find("div", {"id": "horiznav_nav"}).parent.findAll(
"div", {"class": "updatesBar"}):
cat = f"Score-{s.parent.parent.parent.find('td', class_='score-label').text}"
v = ([x.strip() for x in s.parent.text.split("%")][-1].strip("(votes)"))
anime_info[cat] = str(v).strip()
return anime_info
# Helper function to write dict to csv as a new row
def write_new_row(file_name, d):
if not file_name in os.listdir():
with open(file_name,'w', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
headers = list(d.keys())
writer.writerow(headers)
with open(file_name,'a', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
values = []
for k, v in d.items():
values.append(str(v))
writer.writerow(values)
# Scrape various information from the anime title through the links to its webpages
def scrape_anime(anime_id):
#path = f"{HTML_PATH}/{anime_id}"
#if f"{anime_id}.zip" in os.listdir(f'{HTML_PATH}'):
# return
#os.makedirs(path, exist_ok=True)
sleep()
#data = requests.get(f"https://myanimelist.net/anime/{anime_id}", header=req_head)
data = get_request(f"https://myanimelist.net/anime/{anime_id}", req_head, anime_id)
if data is None:
return
soup = BeautifulSoup(data.text, "html.parser")
soup.script.decompose()
va = []
for s in soup.find_all('td', class_='va-t ar pl4 pr4'):
va.append(s.a.text)
#save(f"{HTML_PATH}/{anime_id}/details.html", soup.prettify())
# Get urls to detailed webpages
link_review = get_link_by_text(soup, anime_id, "Reviews")
link_recommendations = get_link_by_text(soup, anime_id, "Recommendations")
link_stats = get_link_by_text(soup, anime_id, "Stats")
#link_staff = get_link_by_text(soup, anime_id, "Characters & Staff")
# Dict to store information
key_list = ['MAL_Id','Name','Synonyms_Name','Japanese_Name','English_Name','Type','Episodes','Status','Aired','Premiered','Producers','Licensors','Studios','Source','Genres','Demographic','Duration','Rating','Score','Ranked','Popularity','Members','Favorites','Watching','Completed','On-Hold','Dropped','Plan to Watch','Total','Score-10','Score-9', 'Score-8', 'Score-7', 'Score-6', 'Score-5', 'Score-4','Score-3', 'Score-2', 'Score-1','Synopsis','Voice_Actors','Recommended_Ids','Recommended_Counts']
anime_info = {key:'?' for key in key_list}
# Scrape relevant information from the urls
anime_info = scrape_anime_info(link_stats, anime_id, anime_info)
anime_info['Synopsis'] = soup.find('p', {'itemprop':'description'}).text.replace('\r','').replace('\n','').replace('\t','')
anime_info['Voice_Actors'] = va
rec_ids, rec_counts = get_recs(link_recommendations, anime_id)
anime_info['Recommended_Ids'] = rec_ids
anime_info['Recommended_Counts'] = rec_counts
write_new_row('anime_info.csv', anime_info)
soup_tags, soup_reviews = get_reviews(link_review, anime_id)
if len(soup_tags) > 0 and len(soup_reviews) > 0:
review_data = get_review_tags(soup_tags, soup_reviews, anime_id)
write_new_reviews('anime_reviews.csv', review_data)
def scrape_all_anime_info(anime_list_file_name, i):
df = pd.read_csv(anime_list_file_name)
for aid in df.Id[i:]:
scrape_anime(aid)
i+=1
print(f'Latest Title: {aid}, Title Completed: {i}/13300')
if not i%20:
print(time.asctime())
Finally, we have our functions that bring everything together. Using BeautifulSoup the relevant information within html tags are retrieved from the subpages and stored within a dictionary for each title. The dictionaries are then written onto disk.
df1 = pd.read_csv('anime_info.csv', on_bad_lines='warn', delimiter='|')
df1
| MAL_Id | Name | Synonyms_Name | Japanese_Name | English_Name | Type | Episodes | Status | Aired | Premiered | ... | Score-6 | Score-5 | Score-4 | Score-3 | Score-2 | Score-1 | Synopsis | Voice_Actors | Recommended_Ids | Recommended_Counts | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 52991 | Sousou no Frieren | Frieren at the Funeral | 葬送のフリーレン | Frieren:Beyond Journey's End | TV | 28 | Finished Airing | Sep 29, 2023 to Mar 22, 2024 | Fall 2023 | ... | 3191 | 1726 | 734 | 426 | 402 | 4100 | During their decade-long quest to defeat the D... | ['Tanezaki, Atsumi', 'Ichinose, Kana', 'Kobaya... | ['33352', '41025', '35851', '486', '457', '296... | ['14', '11', '8', '5', '5', '4', '4', '3', '2'... |
| 1 | 5114 | Fullmetal Alchemist: Brotherhood | Hagane no Renkinjutsushi:Fullmetal Alchemist F... | 鋼の錬金術師 FULLMETAL ALCHEMIST | Fullmetal Alchemist:Brotherhood | TV | 64 | Finished Airing | Apr 5, 2009 to Jul 4, 2010 | Spring 2009 | ... | 31930 | 15538 | 5656 | 2763 | 3460 | 50602 | After a horrific alchemy experiment goes wrong... | ['Park, Romi', 'Kugimiya, Rie', 'Miki, Shinich... | ['11061', '16498', '1482', '38000', '9919', '1... | ['74', '44', '21', '17', '16', '14', '14', '9'... |
| 2 | 9253 | Steins;Gate | ? | STEINS;GATE | Steins;Gate | TV | 24 | Finished Airing | Apr 6, 2011 to Sep 14, 2011 | Spring 2011 | ... | 31520 | 16580 | 8023 | 3740 | 2868 | 10054 | Eccentric scientist Rintarou Okabe has a never... | ['Miyano, Mamoru', 'Imai, Asami', 'Hanazawa, K... | ['31043', '31240', '9756', '10620', '2236', '4... | ['132', '130', '48', '26', '24', '19', '19', '... |
| 3 | 28977 | Gintama° | Gintama' (2015) | 銀魂° | Gintama Season 4 | TV | 51 | Finished Airing | Apr 8, 2015 to Mar 30, 2016 | Spring 2015 | ... | 6060 | 3601 | 1496 | 1011 | 1477 | 8616 | Gintoki, Shinpachi, and Kagura return as the f... | ['Sugita, Tomokazu', 'Kugimiya, Rie', 'Sakaguc... | ['9863', '30276', '33255', '37105', '6347', '3... | ['3', '2', '1', '1', '1', '1', '1', '1', '1', ... |
| 4 | 38524 | Shingeki no Kyojin Season 3 Part 2 | ? | 進撃の巨人 Season3 Part.2 | Attack on Titan Season 3 Part 2 | TV | 10 | Finished Airing | Apr 29, 2019 to Jul 1, 2019 | Spring 2019 | ... | 22287 | 8112 | 3186 | 1596 | 1308 | 12803 | Seeking to restore humanity's diminishing hope... | ['Kamiya, Hiroshi', 'Kaji, Yuuki', 'Ishikawa, ... | ['28623', '37521', '25781', '2904', '36649', '... | ['1', '1', '1', '1', '1', '1', '1', '1', '1', ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 13295 | 49369 | Shinkai no Survival! | Kagaku Manga Survival | 深海のサバイバル! | ? | Movie | 1 | Finished Airing | Aug 13, 2021 | ? | ... | 7 | 5 | 2 | 3 | 2 | 7 | Second movie of Kagaku Manga Surivival learnin... | [] | [] | [] |
| 13296 | 57798 | Shinkalion: Change the World | ? | シンカリオン チェンジ ザ ワールド | ? | TV | Unknown | Currently Airing | Apr 7, 2024 to ? | Spring 2024 | ... | 31 | 34 | 15 | 7 | 3 | 5 | Once upon a time, an unidentified enemy, the U... | ['Tsuchiya, Shinba', 'Ono, Kensho', 'Ishibashi... | [] | [] |
| 13297 | 38114 | Shinkansen Henkei Robo Shinkalion The Animatio... | Shinkansen Henkei Robo Shinkalion:Soushuuhen -... | 【新幹線変形ロボ シンカリオン】総集編『団らん!!速杉家とシンカリオン』 | Bullet Train Transforming Robot Shinkalion The... | ONA | 1 | Finished Airing | Aug 2, 2018 | ? | ... | 16 | 24 | 6 | 3 | 3 | 20 | No synopsis information has been added to this... | [] | [] | [] |
| 13298 | 22313 | Shinken Densetsu: Tight Road | True Fist Legend | 真拳伝説 タイトロード | ? | TV | 13 | Finished Airing | Oct 7, 1994 to Dec 28, 1994 | Fall 1994 | ... | 12 | 14 | 8 | 3 | 2 | 9 | No synopsis information has been added to this... | ['Kamiyama, Masami'] | [] | [] |
| 13299 | 34697 | Shinmai | ? | 新米 | ? | Special | 4 | Finished Airing | Apr 15, 2008 | ? | ... | 2 | 9 | 6 | 11 | 7 | 6 | Everyone is brand new (shinmai) at the beginni... | [] | [] | [] |
13300 rows × 43 columns
The above dataframe shows the final scraped dataset for all 13300 titles, containing significantly more information than what we had in the previous section.
df2 = pd.read_csv('anime_reviews.csv', delimiter='|', on_bad_lines='warn')
df2
| MAL_Id | Review | Tags | |
|---|---|---|---|
| 0 | 52991 | \r\n With lives so short, why d... | ['Recommended', 'Preliminary'] |
| 1 | 52991 | \r\n Frieren is the most overra... | ['Not-Recommended', 'Funny', 'Preliminary'] |
| 2 | 52991 | \r\n I feel so catered to.\r\n\... | ['Recommended'] |
| 3 | 52991 | \r\n Style-\r\r\nFrieren doesn'... | ['Not-Recommended', 'Funny'] |
| 4 | 52991 | \r\n Through 3 episodes, Friere... | ['Mixed-Feelings', 'Preliminary'] |
| ... | ... | ... | ... |
| 77912 | 3287 | \r\n Anime is and always has be... | ['Not-Recommended'] |
| 77913 | 3287 | \r\n If you've come to watch a ... | ['Not-Recommended'] |
| 77914 | 3287 | \r\n Giant Sqid Thingy is muh w... | ['Recommended'] |
| 77915 | 3287 | \r\n "It is not the fault of th... | ['Recommended'] |
| 77916 | 3287 | \r\n "Tenkuu Danzai Skelter+Hea... | ['Recommended'] |
77917 rows × 3 columns
The above dataframe shows the scraped reviews data with their corresponding title id, allowing the possibility of using it for some text based collaborative recommendation system or some sentiment analysis in general.
4. Conclusion
In this notebook we have went through the process of scraping a sizeable dataset for future use. In the next part we will scrape user data from the same site using a different strategy.