Anime webscraping - Part 2

Contents
1. Introduction
In this notebook we be scrape a popular anime database/community MyAnimeList, aiming to collect enough raw data from the anime titles available on the website for further processing and learning purposes.
In Part 1 we have scraped datasets containing information from the anime titles and reviews from the site through HTTP requests to the site and scraping the HTML pages. Here in Part 2 we will still be sending requests but we will include the use of the website’s official API as well.
The relevant python scripts and samples of the datasets can be found in the following repository.
import os
from bs4 import BeautifulSoup
import requests
import time
import pandas as pd
import numpy as np
import random
import csv
2. Usernames Scraping
As there are no easy way to obtain a list of users on the site, a few different approaches were considered.
- Scrape anime titles’ webpages and retrieve lists of usernames that have recently added the title to their rating lists.
- Scrape discussion threads and retrieve all usernames that have participated in the threads.
- Scrape the users webpage periodically to gather a list of usernames that have been active recently.
We are proceeding with the third approach due to the below considerations
- Approach 3 gives us users that are guaranteed to be active, the other approaches may return inactive users depending on the age of the discussion threads or the popularity of an anime title.
- Approaches 1 and 2 may introduce more biases to the sample of usernames we scrape. For Approach 1 we have to consider how we sample the anime titles that we choose to scrape to prevent oversampling users that seek our specific genres. Approach 2 will also have the sample issue with sampling of discussion threads, along with removing all the users who do not take part in these threads.
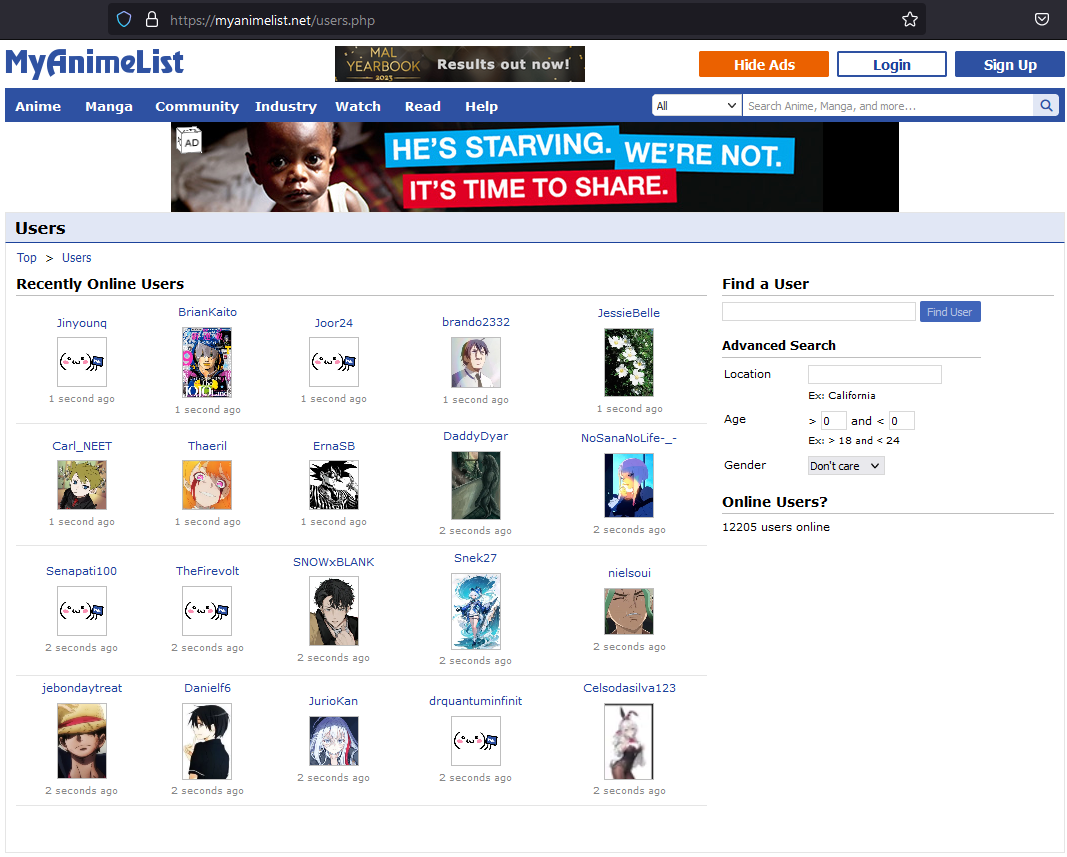
Below image shows the user page that we will scrape, we can see that each time we send a request it should return a response of 20 recently active users. If we do this periodically we will gather a large enough pool of usernames over time.
### Implement randomized sleep time in between requests to reduce chance of being blocked from site
def sleep(t):
rand_t = random.random() * (t) + t
time.sleep(rand_t)
print(f"Sleeping for {rand_t}s")
# Helper function to write list values to csv as a new row
def write_new_row(file_name, l):
with open(file_name,'a', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
values = []
for v in l:
writer.writerow([v])
# Function to scrape usernames page
def get_data(link, req_head):
for _ in range(3):
try:
sleep(0.5)
data = requests.get(link, headers = req_head)
if data.status_code == 403:
print('-----------------------------403 error encountered, may have been rate limited or user list is restricted-----------------------------')
#sleep(300)
return None
elif data.status_code != 200:
print( f'-----------------------------{data.status_code} status code encountered-----------------------------')
sleep(5)
continue
else:
return data
except:
buffer_t = random.random() * (40) + 100
sleep(buffer_t)
continue
print("-----------------------------Error getting request-----------------------------")
print(time.asctime())
Similar to part 1, above are some self explanatory functions that are used.
# Function to extract username data from page
def extract_usernames(data, current_set):
doc = BeautifulSoup(data.text)
usernames = []
for d in doc.find_all('td', class_='borderClass'):
username = d.find('div').text
if username not in current_set:
usernames.append(username)
return usernames
# Scrape usernames from the user page periodically
def scrape_users(req_head, file_name='usernames_list.csv', target=20000):
current_set = set(pd.read_csv(file_name, delimiter='|', header=None).values.ravel())
i = 0
#req_head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0'}
while i < target:
data = get_data('https://myanimelist.net/users.php', req_head)
usernames = extract_usernames(data, current_set)
current_set.update(usernames)
write_new_row(file_name, usernames)
i = len(current_set)
print(f'Current number of usernames found: {i}')
Above we see the functions used for scraping the users page. The first function extracts the usernames from the response html while the second function contains the overall logic to periodically scrape the webpage until enough unique usernames are obtained. A set is used to track and identify unique usernames.
usernames = pd.read_csv('usernames.csv', delimiter='|', header=None).iloc[:,0]
usernames
0 flerbz
1 ArnauCP
2 KelvinKanbaru
3 vian11231123
4 Cidkagenou1997
...
20006 Dolphtaro
20007 AsUkA234
20008 Josetrox
20009 grabahan
20010 mintcakee
Name: 0, Length: 20011, dtype: object
Above we see that we have successfully scraped 20010 active unique usernames.
3. User Ratings List Scraping
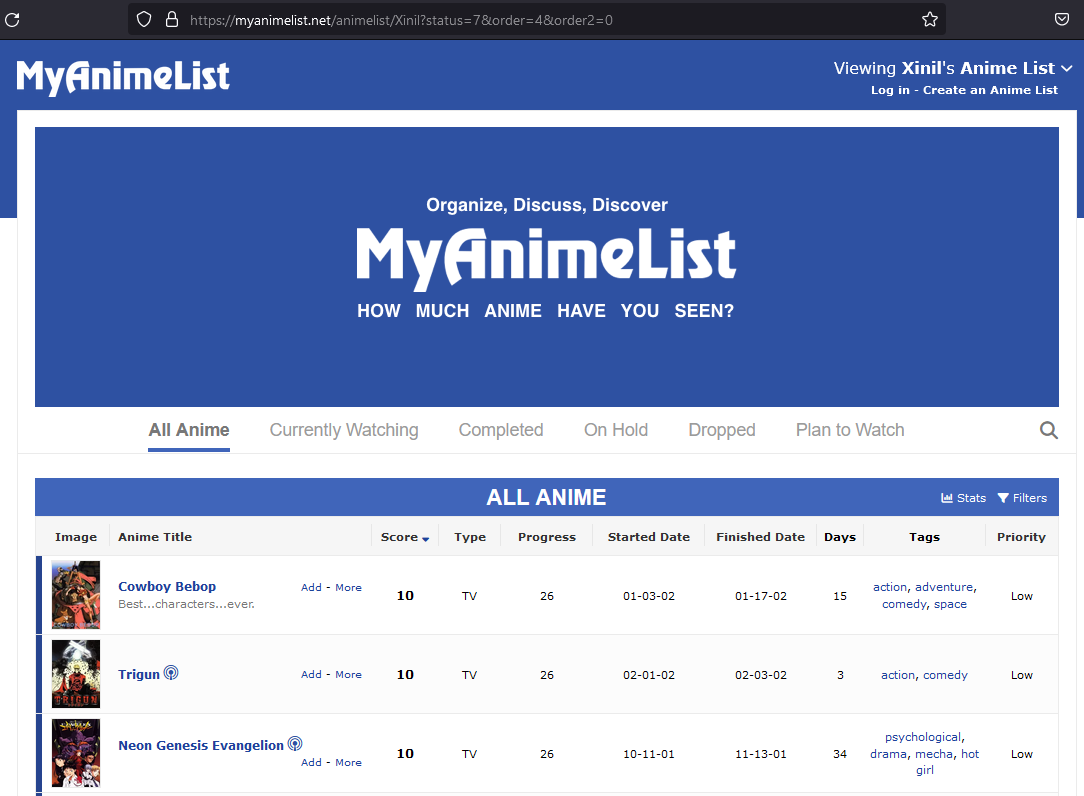
With the usernames available, we are able to scrape their anime ratings list for the desired information. Below is a screenshot of what such as list may look like.
# Extract json details into a list of dict
def get_anime_list(data, user_name, pos, ratings_list):
for i in range(len(data.json()['data'])):
json = data.json()['data'][i]
rating_entry = {
"Username" : user_name,
"User_Id" : pos,
"Anime_Id" : json['node'].get('id', np.nan),
"Anime_Title" : json['node'].get('title', np.nan),
"Rating_Status" : json['list_status'].get('status', np.nan),
"Rating_Score" : json['list_status'].get('score', np.nan),
"Num_Epi_Watched" : json['list_status'].get('num_episodes_watched', np.nan),
"Is_Rewatching" : json['list_status'].get('is_rewatching', np.nan),
"Updated" : json['list_status'].get('updated_at', np.nan),
"Start_Date" : json['list_status'].get('start_date', np.nan)
}
ratings_list.append(rating_entry)
return ratings_list
# Helper function to write dict to csv as a new row
def write_new_row_dict(file_name, d):
if not file_name in os.listdir():
with open(file_name,'w', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
headers = list(d[0].keys())
writer.writerow(headers)
with open(file_name,'a', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='|',lineterminator='\n')
for i in range(1,len(d)):
values = []
for k, v in d[i].items():
values.append(str(v))
writer.writerow(values)
# Scrape anime list information of each username within the list of usernames
def scrape_user_animelist(usernames, req_head, pos, log_file, output_file):
curr = 0 # track consecutive skipped users, to differentiate rate limiting vs user's restricted list
while pos < len(usernames):
# if 403 error encountered more than 3 times in a row, sleep for ~5 minutes due to suspected rate limiting
if curr > 3:
print("Suspected rate limiting, pausing for a few minutes")
sleep(240)
username = usernames[pos]
animelist_link = f'https://api.myanimelist.net/v2/users/{username}/animelist?limit=500&nsfw=true&fields=list_status'
ratings_list= []
data = get_data(animelist_link, req_head)
# log the users that were skipped due to 403 error, this can happen if website rate limits us or if the user has chosen to keep their list private/restricted.
if data is None:
print(f'Current number of usernames processed: {pos} / {len(usernames)}')
print(f'Skipping user {pos} as rate limited or user list is restricted')
write_new_row_dict('skipped_users_list.csv', [{'pos':pos, "username":username}])
curr += 1
pos += 1
continue
curr = 0
ratings_list = get_anime_list(data, usernames[pos], pos, ratings_list)
if len(ratings_list):
write_new_row_dict('user_ratings.csv', ratings_list)
print(f'Current number of usernames processed: {pos} / {len(usernames)}')
pos += 1
Once we have a list of usernames, we will be calling the website’s official API to retrieve the anime rating lists from each of these users. Similar to how we did it for anime titles, the information for each user will be stored in dictionaries.
When requesting users that have restricted access to their anime rating lists, a 403 status code will be returned by the API. This is the same response given if we get rate limited when using the API. To prevent the script from unnecessarily pausing when encountering restricted usernames, we placed a condition so that time delay to let any rate limitation expire will only trigger after encountering 403 response 4 times in a row. These 403 errors are also logged for further investigation if requried.
With the official API, retrieving data is a lot simpler as everything is structured properly within the json, avoiding the need to make sense of the webpage’s html and identify which tags to retrieve.
user_ratings = pd.read_csv('user_ratings.csv', delimiter='|')
user_ratings
| Username | User_Id | Anime_Id | Anime_Title | Rating_Status | Rating_Score | Num_Epi_Watched | Is_Rewatching | Updated | Start_Date | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | flerbz | 0 | 30654 | Ansatsu Kyoushitsu 2nd Season | watching | 0 | 24 | False | 2022-02-26T22:15:01+00:00 | 2022-01-29 |
| 1 | flerbz | 0 | 22789 | Barakamon | dropped | 0 | 2 | False | 2023-01-28T19:03:33+00:00 | 2022-04-06 |
| 2 | flerbz | 0 | 31964 | Boku no Hero Academia | completed | 0 | 13 | False | 2024-03-31T02:10:32+00:00 | 2024-03-30 |
| 3 | flerbz | 0 | 33486 | Boku no Hero Academia 2nd Season | completed | 0 | 25 | False | 2024-03-31T22:32:02+00:00 | 2024-03-30 |
| 4 | flerbz | 0 | 36456 | Boku no Hero Academia 3rd Season | watching | 0 | 24 | False | 2024-04-03T02:08:56+00:00 | 2024-03-31 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5452187 | mintcakee | 20010 | 392 | Yuu☆Yuu☆Hakusho | plan_to_watch | 0 | 0 | False | 2023-03-09T13:18:23+00:00 | NaN |
| 5452188 | mintcakee | 20010 | 1246 | Yuugo: Koushounin | plan_to_watch | 0 | 0 | False | 2023-10-23T14:14:44+00:00 | NaN |
| 5452189 | mintcakee | 20010 | 23283 | Zankyou no Terror | plan_to_watch | 0 | 0 | False | 2022-12-29T02:18:00+00:00 | NaN |
| 5452190 | mintcakee | 20010 | 37976 | Zombieland Saga | completed | 7 | 12 | False | 2023-04-24T14:35:42+00:00 | NaN |
| 5452191 | mintcakee | 20010 | 40174 | Zombieland Saga Revenge | completed | 8 | 12 | False | 2023-04-24T14:35:46+00:00 | NaN |
5452192 rows × 10 columns
Our final scraped user ratings list data contains over 5.4 million entries. Before even accounting for the requests that returned a 403 error we see that on average each user has about 270 titles within their list! With this information we may be able to form some sort of collaborative recommendation system where we use these ratings to gauge how well another user may like a title they have not watched.
4. Conclusion
In this notebook we went through the process of scraping a dataset containing ~20000 users and their ratings for anime titles that they have watched. Using this as raw data, further analysis and applications can be explored.