Posts listed under tag: classification
-
 May 30, 2024
In this notebook we will be working on the following Kaggle Challenge on a flood detection problem where the goal is to predict the probability of a region flooding based on various factors.
May 30, 2024
In this notebook we will be working on the following Kaggle Challenge on a flood detection problem where the goal is to predict the probability of a region flooding based on various factors.
-
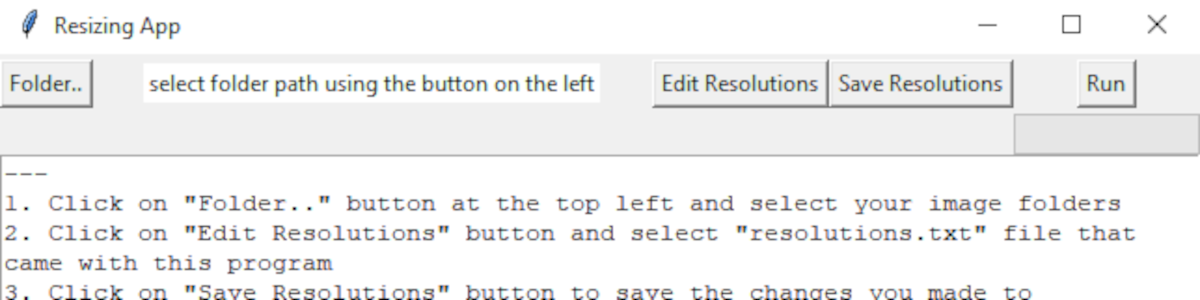 Apr 24, 2024
Built a simple application through Python, utilizing deep learning techniques to automatically process e-commerce product photos into desired framings and resolutions saving the user from completing the very tedious and time consuming task.
Apr 24, 2024
Built a simple application through Python, utilizing deep learning techniques to automatically process e-commerce product photos into desired framings and resolutions saving the user from completing the very tedious and time consuming task.
-
 Apr 22, 2024
Global retail e-commerce sales reached an estimated 5.8 trillion USD in 2023. A major component of retail e-commerce are the products and the product images that showcases these products to the customers. With the number of platforms that sellers can promote their wide inventory of products, tailoring high quality product images for each platform may be a menial task consuming significant man-hours. With the help of YOLOv8 by ultralytics I aim to automate the creation of these product images.
Apr 22, 2024
Global retail e-commerce sales reached an estimated 5.8 trillion USD in 2023. A major component of retail e-commerce are the products and the product images that showcases these products to the customers. With the number of platforms that sellers can promote their wide inventory of products, tailoring high quality product images for each platform may be a menial task consuming significant man-hours. With the help of YOLOv8 by ultralytics I aim to automate the creation of these product images.
-
 Mar 15, 2024
In this notebook we will explore a synthetic bank customer churn dataset used in a Kaggle community prediction competition, treating this like a real world problem and avoiding the use of any performance-boosting tricks that is are only specific to this competition dataset (i.e. utilizing data leakages due to the syntheticity of the data.
Mar 15, 2024
In this notebook we will explore a synthetic bank customer churn dataset used in a Kaggle community prediction competition, treating this like a real world problem and avoiding the use of any performance-boosting tricks that is are only specific to this competition dataset (i.e. utilizing data leakages due to the syntheticity of the data.
-
 Mar 13, 2024
In this notebook we take a look at a [Kaggle Playground Series](https://www.kaggle.com/competitions/playground-series-s4e2) competition where users submit their predictions for a multi-class classification problem on the sample's weight class.
Mar 13, 2024
In this notebook we take a look at a [Kaggle Playground Series](https://www.kaggle.com/competitions/playground-series-s4e2) competition where users submit their predictions for a multi-class classification problem on the sample's weight class.
-
 Feb 20, 2024
In this notebook we will be exploring the IMDB dataset available on Kaggle, containing 50,000 reviews categorised as either positive or negative reviews. A text classification model will then be fine-tuned over DistilBERT and evaluated.
Feb 20, 2024
In this notebook we will be exploring the IMDB dataset available on Kaggle, containing 50,000 reviews categorised as either positive or negative reviews. A text classification model will then be fine-tuned over DistilBERT and evaluated.
-
 Feb 2, 2024
Capstone project for Google's Advanced Data Analytics Course on Coursera, simulating a scenario where the HR department of a large consulting firm is looking for insights from our data analysis and predictions on employee churn data.
Feb 2, 2024
Capstone project for Google's Advanced Data Analytics Course on Coursera, simulating a scenario where the HR department of a large consulting firm is looking for insights from our data analysis and predictions on employee churn data.
-
 Jan 1, 2024
In this notebook we train classification models to identify the activities and subjects from a smartphone sensor dataset.
Jan 1, 2024
In this notebook we train classification models to identify the activities and subjects from a smartphone sensor dataset.
-
 Jan 1, 2024
In this notebook we will be using an autoencoder on the fraud dataset used in a previous notebook for novelty detection. Novelty detection refers to the identification of new or unknown signals not available to a machine learning system during training. In this case it refers to training a machine learning model only on normal(non-fradulent) transactions data but the resultant model has the ability to recognise fraudulent transactions.
Jan 1, 2024
In this notebook we will be using an autoencoder on the fraud dataset used in a previous notebook for novelty detection. Novelty detection refers to the identification of new or unknown signals not available to a machine learning system during training. In this case it refers to training a machine learning model only on normal(non-fradulent) transactions data but the resultant model has the ability to recognise fraudulent transactions.
-
 Jan 1, 2024
In this notebook we train classification models to identify the activities and subjects from a smartphone sensor dataset.
Jan 1, 2024
In this notebook we train classification models to identify the activities and subjects from a smartphone sensor dataset.
-
Jan 1, 2024
This notebook explores a dataset of credit card transactions over a span of two days, analysing the data and tackling the extremely imbalanced classification problem of fraud detection.
1
numpy
pandas
matplotlib
seaborn
scikit-learn
classification
statistics
nlp
fun
scipy
dimensionality_reduction
webscrape
tensorflow
computer_vision
requests
html
bs4
transfer_learning
regression
pytorch
nltk
multiprocessing
kaggle
generative_ai
featured
competition
transformers
statsmodels
statsmodel
sql
recommendation
ollama
object_detection
langchain
forecast
flask
embedding
database
cv2
automation
api
tkinter
statistics
math
gradio