Object Detection with YOLOv8 for Product Images

Contents
- Introduction
- Training the Model
- Test Clothes/Person Detection
- Crop and Resize/Extend Detected Image
- Conclusion
1. Introduction
Global retail e-commerce sales reached an estimated 5.8 trillion USD in 2023. A major component of retail e-commerce are the products and the product images that showcases these products to the customers. With the number of platforms that sellers can promote their wide inventory of products, tailoring high quality product images for each platform may be a menial task consuming significant man-hours. With the help of YOLOv8 by ultralytics I aim to automate the creation of these product images.
For demonstration purposes I will be focusing on apparel products, training a model for this purpose using a dataset found on Kaggle.
2. Training the Model
The dataset comes with 12,000 images split into a training (10,000) and a validation (2,000) set and their corresponding annotation text file.
The annotation tells us two thing:
- Category Id -> Target Id
- Bounding Box -> Coordinates of upper left and bottom right corners of bounding box
import numpy as np
import cv2
from ultralytics import YOLO
from IPython.display import Image, display
import PIL
import yaml
import os
import matplotlib.pyplot as plt
filename = f'images/train/020724.jpg'
image = cv2.imread(filename)
height = np.size(image, 0)
width = np.size(image, 1)
print(f"Image Resolution: {height}, {width}")
Image Resolution: 702, 468
Image(filename)

Taking a look at a sample image above, we have the contents of its annotation below in the format
target_class x1 y1 x2 y2
7 0.5470085470085471 0.5498575498575499 0.3034188034188034 0.5270655270655271
3 0.5448717948717948 0.2272079772079772 0.5555555555555556 0.4544159544159544
The above tells us that two target classes are within this image: 7-> trousers at (0.5470085470085471, 0.5498575498575499) (0.3034188034188034, 0.5270655270655271) 3-> long sleever outerwear at (0.5448717948717948, 0.2272079772079772) (0.5555555555555556, 0.4544159544159544)
yaml_config = {'train': 'images/train/',
'val': 'images/val/',
'nc': 13,
'names': ['short_sleeve_top','long_sleeve_top','short_sleeve_outer_top','long_sleeve_outer_top','vest_top','sling_top','shorts_bottom','trousers_bottom','skirt_bottom','short_sleeve_dress_full','long_sleeve_dress_full','vest_dress_full','sling_dress_full']
}
with open('config.yaml', 'w') as f:
yaml.dump(yaml_config, f, default_flow_style=False)
In the above cell I have created a yaml file that contains dataset-specific parameters that will be provided to our model, namely the training dataset filepath, validation dataset filepath, number of target classes, and string labels for our target classes.
In my disk the dataset is formatted in the following manner:
- Training Data : ./images/train/
- Validation Data : ./images/val/
- Training Labels : ./labels/train/
- Validation Labels : ./labels/val/
model = YOLO("yolov8m.pt")
results = model.train(data='config.yaml', epochs=50, patience=5, save_period=5)
[34m[1mengine\trainer: [0mtask=detect, mode=train, model=yolov8m.pt, data=config.yaml, epochs=50, time=None, patience=5, batch=16, imgsz=640, save=True, save_period=5, cache=False, device=None, workers=8, project=None, name=train2, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml
Overriding model.yaml nc=80 with nc=13
from n params module arguments
0 -1 1 1392 ultralytics.nn.modules.conv.Conv [3, 48, 3, 2]
1 -1 1 41664 ultralytics.nn.modules.conv.Conv [48, 96, 3, 2]
2 -1 2 111360 ultralytics.nn.modules.block.C2f [96, 96, 2, True]
3 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
4 -1 4 813312 ultralytics.nn.modules.block.C2f [192, 192, 4, True]
5 -1 1 664320 ultralytics.nn.modules.conv.Conv [192, 384, 3, 2]
6 -1 4 3248640 ultralytics.nn.modules.block.C2f [384, 384, 4, True]
7 -1 1 1991808 ultralytics.nn.modules.conv.Conv [384, 576, 3, 2]
8 -1 2 3985920 ultralytics.nn.modules.block.C2f [576, 576, 2, True]
9 -1 1 831168 ultralytics.nn.modules.block.SPPF [576, 576, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 2 1993728 ultralytics.nn.modules.block.C2f [960, 384, 2]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 2 517632 ultralytics.nn.modules.block.C2f [576, 192, 2]
16 -1 1 332160 ultralytics.nn.modules.conv.Conv [192, 192, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 2 1846272 ultralytics.nn.modules.block.C2f [576, 384, 2]
19 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 2 4207104 ultralytics.nn.modules.block.C2f [960, 576, 2]
22 [15, 18, 21] 1 3783223 ultralytics.nn.modules.head.Detect [13, [192, 384, 576]]
Model summary: 295 layers, 25863847 parameters, 25863831 gradients, 79.1 GFLOPs
Starting training for 50 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/50 6.82G 0.9247 1.948 1.347 57 640: 100%|██████████| 625/625 [03:10<00:00,
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:20
all 2000 3313 0.592 0.403 0.409 0.293
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
11/50 6.73G 0.7823 1.132 1.209 72 640: 100%|██████████| 625/625 [03:01<00:00,
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:34
all 2000 3313 0.695 0.544 0.602 0.487
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
21/50 6.74G 0.6947 0.9277 1.152 61 640: 100%|██████████| 625/625 [03:03<00:00,
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:43
all 2000 3313 0.723 0.599 0.692 0.582
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
31/50 6.74G 0.6281 0.7725 1.097 54 640: 100%|██████████| 625/625 [03:11<00:00,
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:40
all 2000 3313 0.68 0.681 0.727 0.619
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
37/50 6.74G 0.6022 0.6965 1.09 54 640: 100%|██████████| 625/625 [03:09<00:00,
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:28
all 2000 3313 0.719 0.682 0.726 0.621
[34m[1mEarlyStopping: [0mTraining stopped early as no improvement observed in last 5 epochs. Best results observed at epoch 32, best model saved as best.pt.
To update EarlyStopping(patience=5) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 63/63 [00:12
all 2000 3313 0.72 0.671 0.74 0.632
short_sleeve_top 2000 806 0.855 0.872 0.941 0.821
long_sleeve_top 2000 347 0.776 0.723 0.814 0.683
short_sleeve_outer_top 2000 13 0.57 0.385 0.518 0.486
long_sleeve_outer_top 2000 111 0.604 0.811 0.799 0.677
vest_top 2000 163 0.709 0.732 0.779 0.64
sling_top 2000 32 0.816 0.344 0.473 0.382
shorts_bottom 2000 269 0.845 0.773 0.869 0.725
trousers_bottom 2000 610 0.85 0.915 0.944 0.765
skirt_bottom 2000 419 0.798 0.773 0.837 0.698
short_sleeve_dress_full 2000 181 0.713 0.685 0.745 0.682
long_sleeve_dress_full 2000 98 0.475 0.531 0.548 0.488
vest_dress_full 2000 197 0.661 0.701 0.733 0.635
sling_dress_full 2000 67 0.684 0.484 0.624 0.53
Speed: 0.1ms preprocess, 4.0ms inference, 0.0ms loss, 0.5ms postprocess per image
We are using to train on top of yolov8m.pt as it is the best performing model that can be trained within a reasonable amount of time on my system. An early stopping mechanism of 5 epochs is defined, training the model for a maximum of 50 epochs.
Early stopping was triggered at epoch 37, identifying the best model at epoch 32. We also see that the entire process of infering an image only takes less than 5ms
results = model.val()
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 125/125 [00:
all 2000 3313 0.726 0.67 0.74 0.631
short_sleeve_top 2000 806 0.857 0.872 0.941 0.822
long_sleeve_top 2000 347 0.779 0.72 0.809 0.678
short_sleeve_outer_top 2000 13 0.578 0.385 0.515 0.483
long_sleeve_outer_top 2000 111 0.613 0.811 0.799 0.677
vest_top 2000 163 0.703 0.724 0.783 0.644
sling_top 2000 32 0.836 0.344 0.47 0.379
shorts_bottom 2000 269 0.848 0.767 0.868 0.725
trousers_bottom 2000 610 0.854 0.915 0.944 0.764
skirt_bottom 2000 419 0.797 0.769 0.837 0.695
short_sleeve_dress_full 2000 181 0.707 0.68 0.743 0.68
long_sleeve_dress_full 2000 98 0.502 0.551 0.549 0.488
vest_dress_full 2000 197 0.67 0.695 0.735 0.636
sling_dress_full 2000 67 0.698 0.478 0.627 0.534
Speed: 0.1ms preprocess, 8.0ms inference, 0.0ms loss, 0.5ms postprocess per image
train_val_dir = 'runs/detect/train22/'
for file in os.listdir(train_val_dir):
if '.png' in file or '.jpg' in file:
print(file)
i = Image(train_val_dir + file)
display(i)
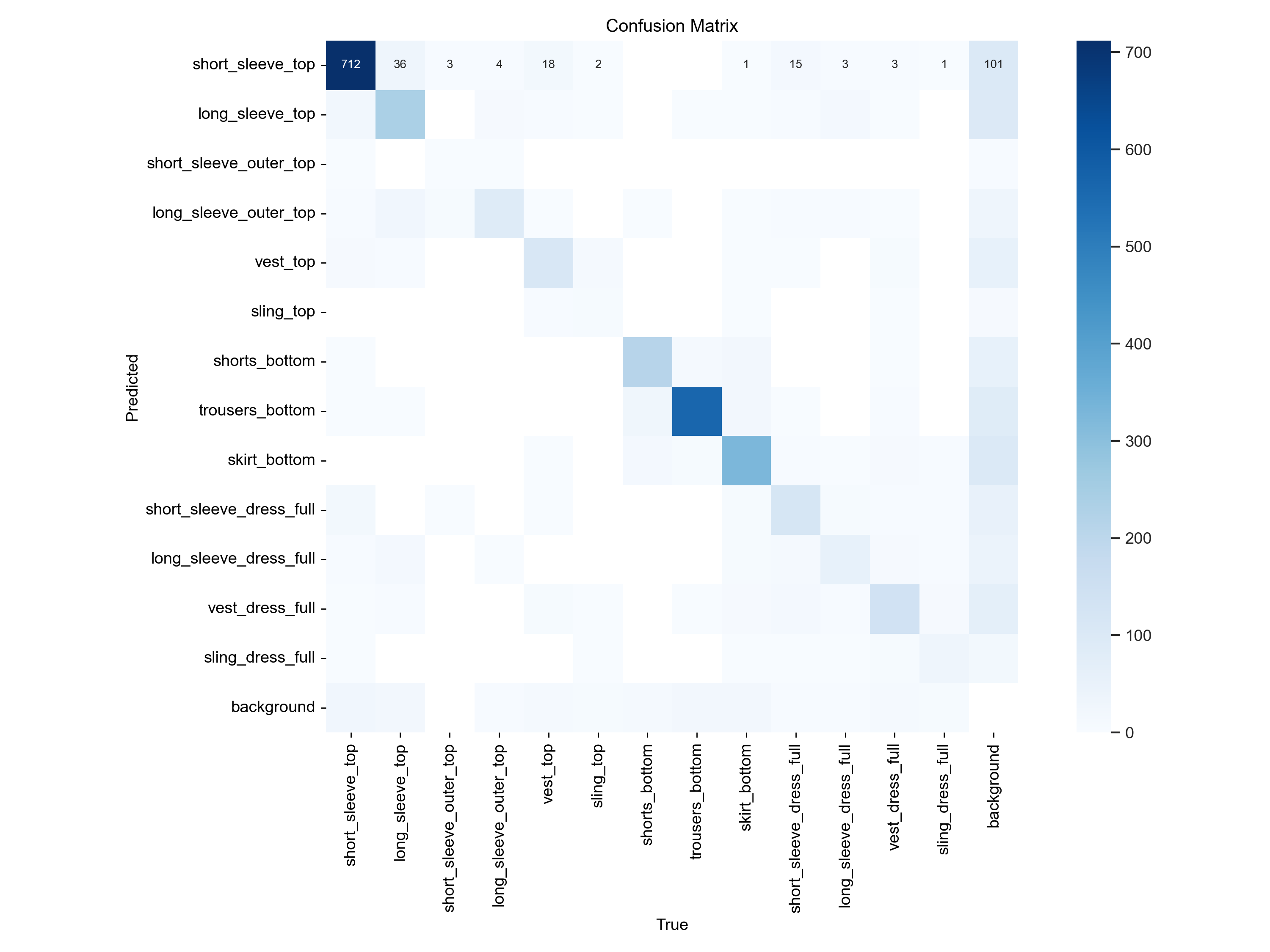
confusion_matrix.png
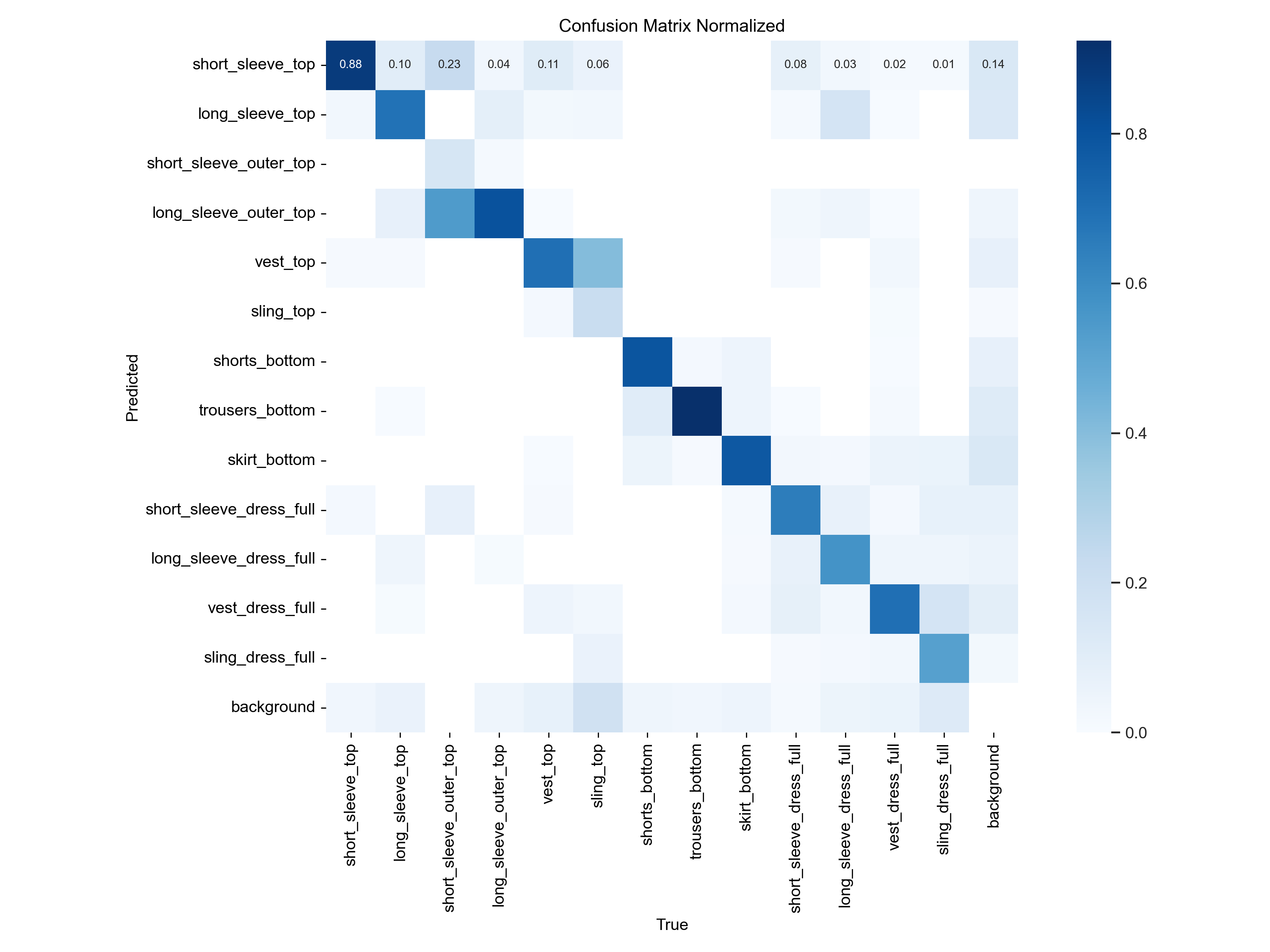
confusion_matrix_normalized.png
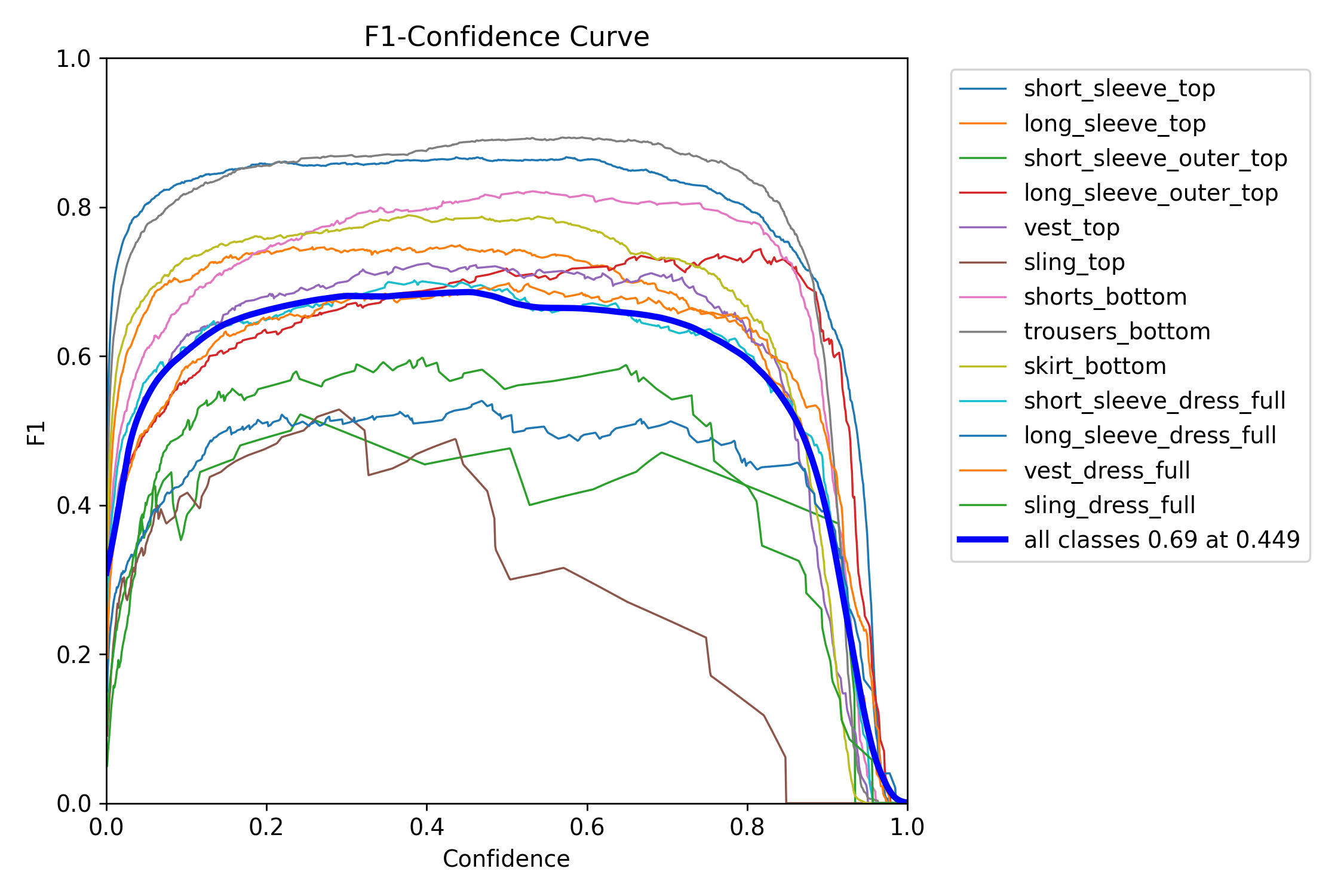
F1_curve.png
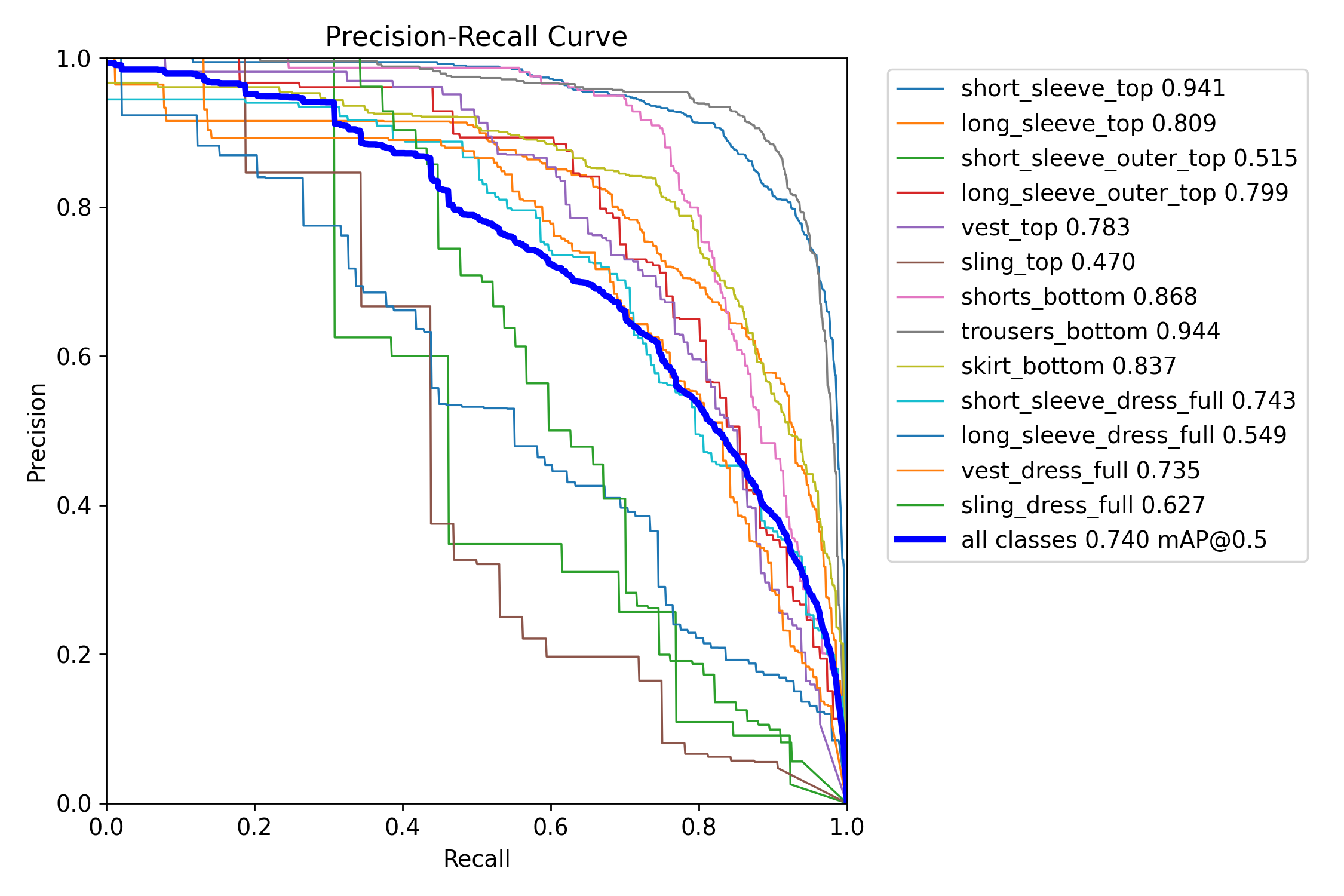
PR_curve.png
P_curve.png
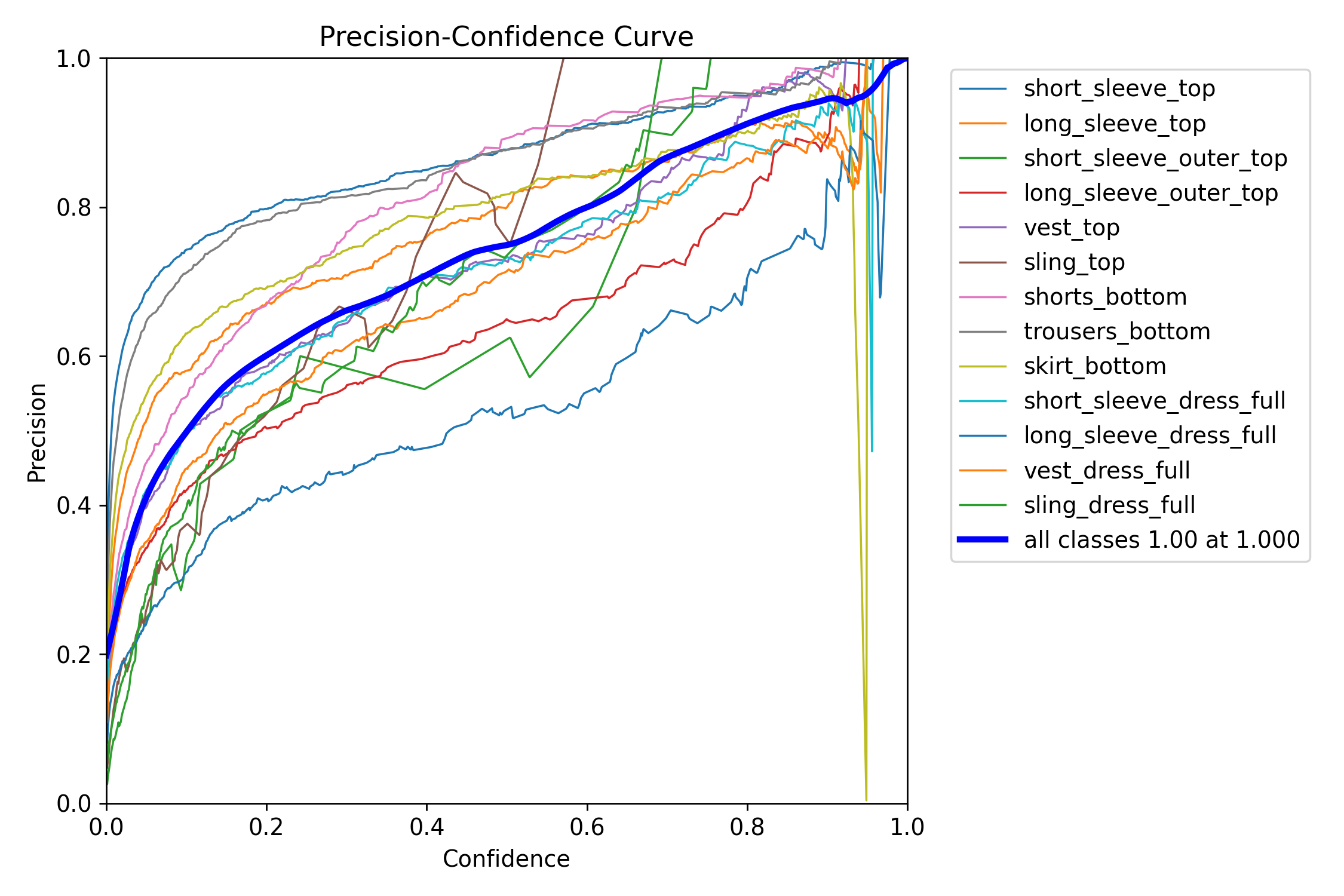
R_curve.png
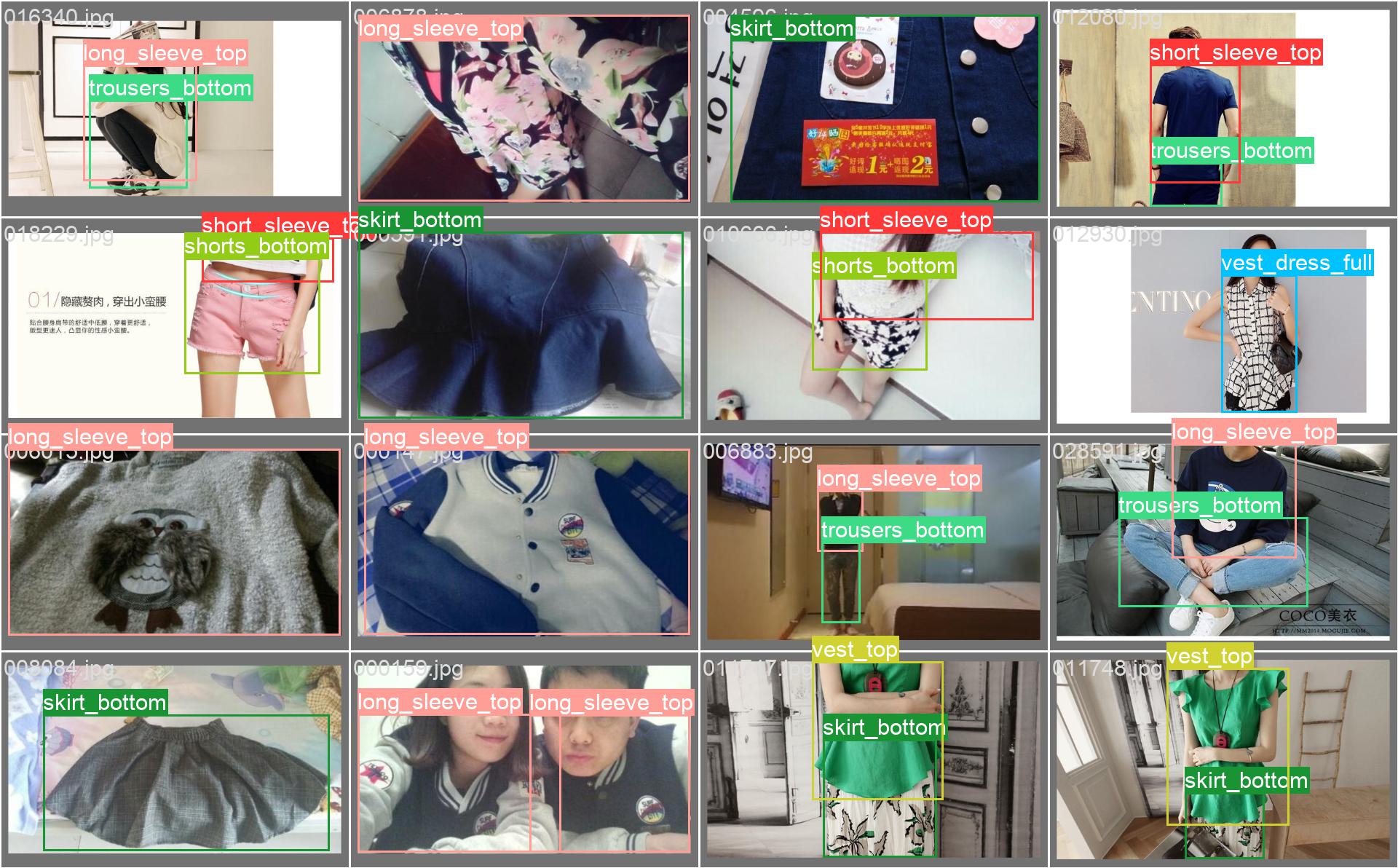
val_batch0_labels.jpg
val_batch0_pred.jpg

val_batch1_labels.jpg

val_batch1_pred.jpg

val_batch2_labels.jpg
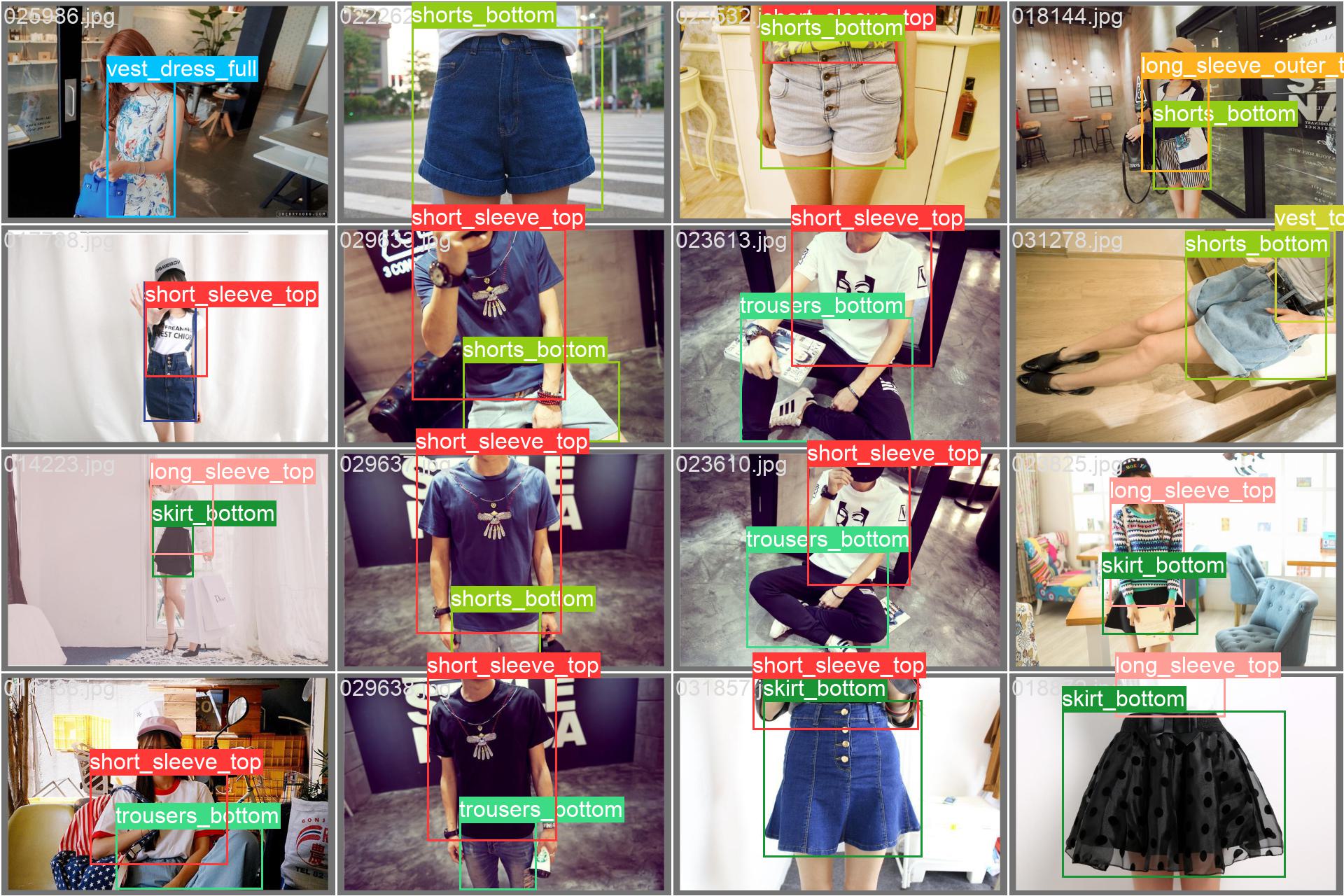
val_batch2_pred.jpg
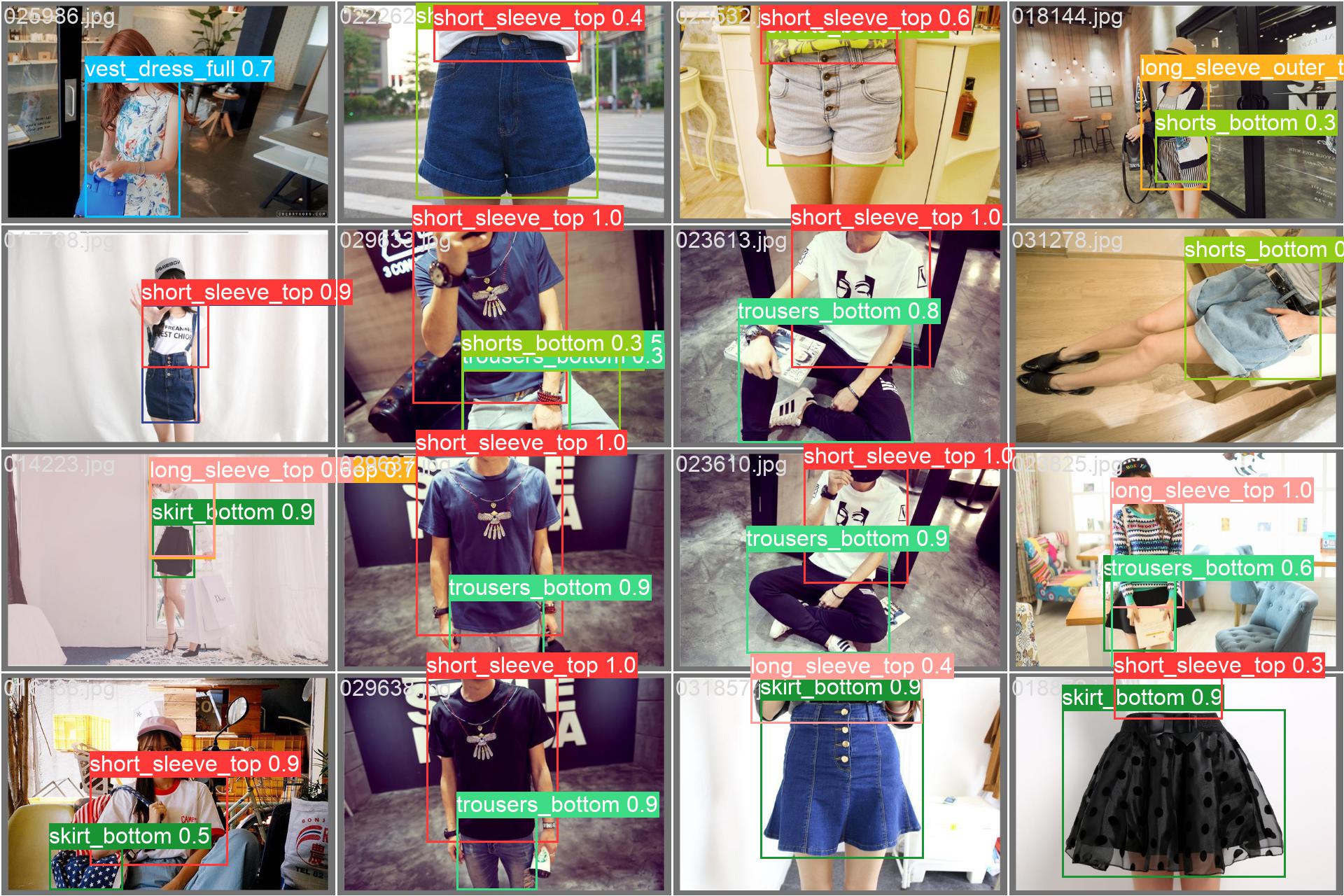
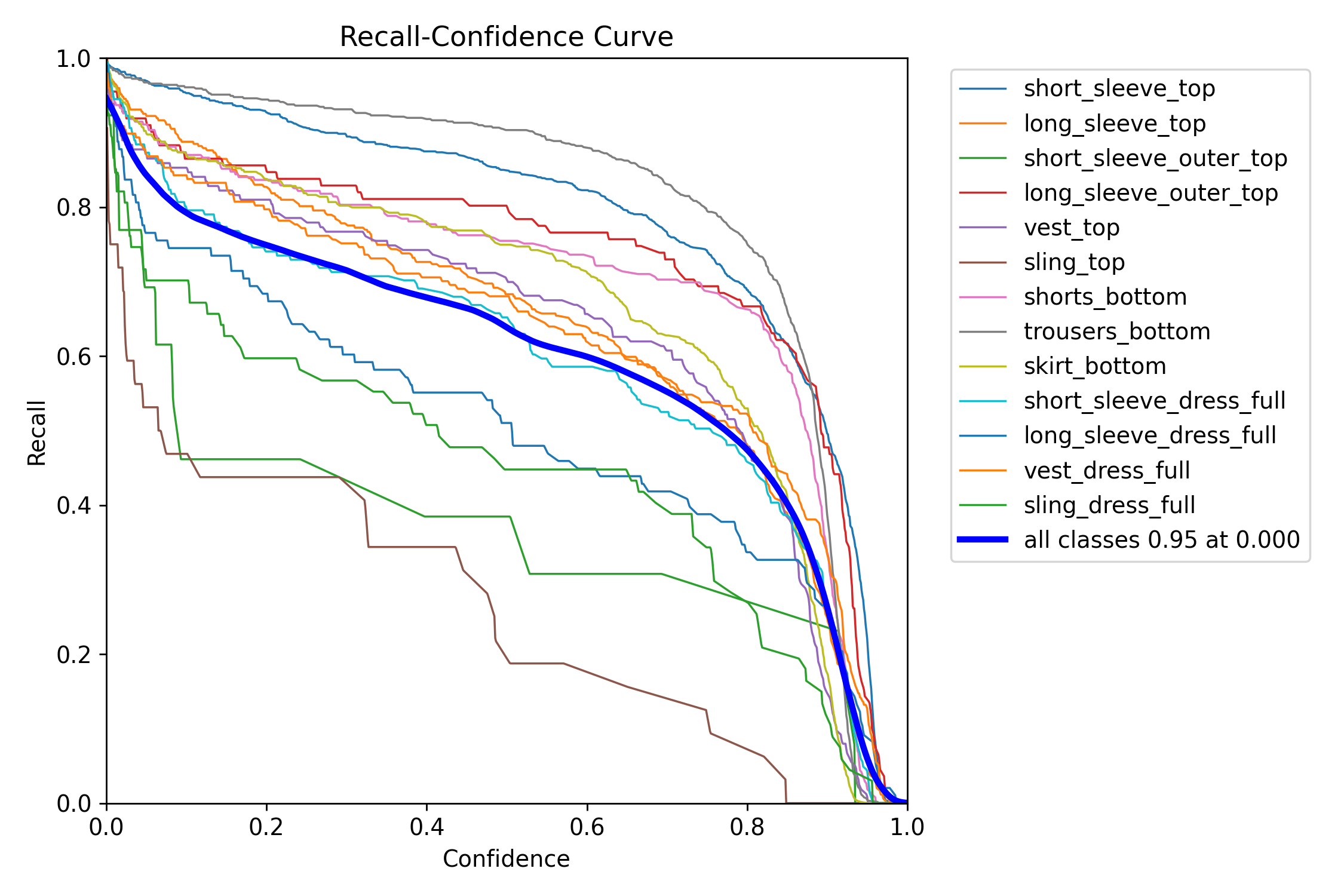
The confusion matrices suggests that model performance is good, on the normalized matrix we see a line of solid blue boxes along the diagonal suggesting that the model is correct predicting the classes of the detected objects. This holds true for all target classes except for short_sleeve_outer_top that seems to be getting misclassified as long_sleeve_outer_top most of the time, and sling_top that appears to be misclassified as vest_top.
Looking at the confidence/P-R curves from the model, we see that model performance was the highest when detecting short_sleeve_tops and_trousers_bottom, whereas dresses and sling_top/sling_dress_full have the worst performances in general
Beyond the curves we can also see examples of the model in action, showing batches of validation images and the objects that the model has identified within.
3. Test Clothes/Person Detection
We will use a stock photo found on Pexels for demonstration purposes.
test_img_path = 'images/pexels-amina-filkins-5560019.jpg'
model = YOLO('models/best.pt')
# only predict for top/bottom clothing pieces, ignore dresses
# if model predicts significant confidence for dress + top/bottom, dress is ignored and next most confident class returned
top_bottom_classes = list(range(9))
res = model(test_img_path, classes=top_bottom_classes)
res[0].boxes
Speed: 2.5ms preprocess, 104.0ms inference, 2.5ms postprocess per image at shape (1, 3, 640, 448)
ultralytics.engine.results.Boxes object with attributes:
cls: tensor([1., 7.], device='cuda:0')
conf: tensor([0.9445, 0.9062], device='cuda:0')
data: tensor([[1.4256e+03, 1.6280e+03, 2.9449e+03, 3.3525e+03, 9.4448e-01, 1.0000e+00],
[1.3619e+03, 3.0014e+03, 2.6809e+03, 5.1548e+03, 9.0623e-01, 7.0000e+00]], device='cuda:0')
id: None
is_track: False
orig_shape: (6000, 4000)
shape: torch.Size([2, 6])
xywh: tensor([[2185.2847, 2490.2532, 1519.3256, 1724.4862],
[2021.3818, 4078.0630, 1318.9542, 2153.3850]], device='cuda:0')
xywhn: tensor([[0.5463, 0.4150, 0.3798, 0.2874],
[0.5053, 0.6797, 0.3297, 0.3589]], device='cuda:0')
xyxy: tensor([[1425.6219, 1628.0101, 2944.9475, 3352.4963],
[1361.9047, 3001.3704, 2680.8589, 5154.7554]], device='cuda:0')
xyxyn: tensor([[0.3564, 0.2713, 0.7362, 0.5587],
[0.3405, 0.5002, 0.6702, 0.8591]], device='cuda:0')
res[0].names
{0: 'short_sleeve_top',
1: 'long_sleeve_top',
2: 'short_sleeve_outer_top',
3: 'long_sleeve_outer_top',
4: 'vest_top',
5: 'sling_top',
6: 'shorts_bottom',
7: 'trousers_bottom',
8: 'skirt_bottom',
9: 'short_sleeve_dress_full',
10: 'long_sleeve_dress_full',
11: 'vest_dress_full',
12: 'sling_dress_full'}
For now we will ignore the dresses target class and focus only on tops and bottoms. From the prediction results of the model we see that classes 1 (long_sleeve_top) and 7 (trousers_bottom) were detected from this image.
test_img_bgr = cv2.imread(test_img_path)
test_img = cv2.cvtColor(test_img_bgr, cv2.COLOR_BGR2RGB)
for r in res[0].boxes.xyxy:
cv2.rectangle(test_img,(int(r[0]) ,int(r[1])), (int(r[2]) ,int(r[3])), color = (255,0,0))
img = PIL.Image.fromarray(test_img)
img = img.resize((img.size[0]//4, img.size[1]//4), PIL.Image.LANCZOS)
display(img)
test_img_bgr = cv2.imread(test_img_path)
test_img = cv2.cvtColor(test_img_bgr, cv2.COLOR_BGR2RGB)
h, w, _ = test_img.shape
for r in res[0].boxes.xyxy:
cropped_img = test_img[int(r[1]):int(r[3]), int(r[0]):int(r[2])]
img = PIL.Image.fromarray(cropped_img)
img = img.resize((img.size[0]//4, img.size[1]//4), PIL.Image.LANCZOS)
display(img)



We see the bounding boxes marked in red, and the resulting images should we decide to crop them as they are appears a little claustrophobic. It may work as product showcase images, but sometimes we may want the images to look more aesthetically pleasing.
test_img_bgr = cv2.imread(test_img_path)
test_img = cv2.cvtColor(test_img_bgr, cv2.COLOR_BGR2RGB)
h, w, _ = test_img.shape
h_pad, w_pad = h//20, w//20
for r in res[0].boxes.xyxy:
cropped_img = test_img[int(r[1])-h_pad:int(r[3])+h_pad, int(r[0])-w_pad:int(r[2]+w_pad)]
img = PIL.Image.fromarray(cropped_img)
img = img.resize((img.size[0]//4, img.size[1]//4), PIL.Image.LANCZOS)
display(img)


By padding the bounding boxes we keep the subject centred while subjectively making it nicer to look at. Another approach we can take is to crop the images in a way that avoids cutting the head/shoes of the model off.
To do that we will make use of a base yolov8 model that will serve as our person detection model. For our purposes the inclusion of this step will be cheap computationally as inference from the model is relatively quick. Additionally, sometimes sellers may want to crop/resize their images in a manner where the entire subject is left untouched.
person_model = YOLO("models/yolov8l.pt")
person_res = person_model(test_img_path, classes=0)
Speed: 6.0ms preprocess, 131.0ms inference, 1821.1ms postprocess per image at shape (1, 3, 640, 448)
test_img_bgr = cv2.imread(test_img_path)
test_img = cv2.cvtColor(test_img_bgr, cv2.COLOR_BGR2RGB)
h, w, _ = test_img.shape
for r in person_res[0].boxes.xyxy:
cv2.rectangle(test_img,(int(r[0]) ,int(r[1])), (int(r[2]) ,int(r[3])), color = (0,0,255))
img = PIL.Image.fromarray(test_img)
img = img.resize((img.size[0]//6, img.size[1]//6), PIL.Image.LANCZOS)
display(img)

From above we see that the bounding box follows the edge of the subject closely, but no part of the subject has been cut off by the box. These two models will serve as the foundation of our automation tool.
4. Crop and Resize/Extend Detected Image
In this section we will further explore how to make our cropped images more aesthetically pleasing and resize them as required.
The working principles behind the approach in this section are the following:
- Crop images with a combination of the product detection and person detection models, a product bounding box supplemented with a full body bounding box can help us better center the relevant subject. Cropped image can then be resized until either height or width is the target resolution.
- Determine if the cropped image will be extended/padded along the width or length after cropping and resizing to achieve the target resolution
- Center the resized image within the target resolution based on the original bounding box
- Create two new arrays, one to store image information after resizing and padding, another to create a mask of the padded region
- Apply blur on masked area to smooth and blend the newly padded background with the original image
Some limitations of this approach, and possible solutions to these limitations:
- Works only for simple backgrounds with mostly solid colors. For complex backgrounds the use of an image generative model for outpainting the padding can be explored.
- In the case of person detection, bounding boxes will include extremities of the person resulting in the person being off-centre for certain poses. Fine tuning the model to detect centre mass/face of the person will help reduce this problem .
Putting everything together we have the three functions below that will handle the logic behind bringing the original image to our final image.
def detect(model, img_path, classes):
return model(img_path, classes=classes)
def crop_image(img_path, product_res, h_pad=-1, w_pad=-1, person_res=None):
product_img_bgr = cv2.imread(img_path)
product_img = cv2.cvtColor(product_img_bgr, cv2.COLOR_BGR2RGB)
h, w, _ = product_img.shape
cropped_imgs = []
paddings = []
product_classes = []
# Amount of pixels to pad the bounding box in all 4 directions
if h_pad == -1:
h_pad = h//10
if w_pad == -1:
w_pad = w//10
for i in range(len(product_res[0].boxes)):
product_class = product_res[0].names[int(product_res[0].boxes.cls[i])]
x1,y1,x2,y2 = product_res[0].boxes.xyxy[i].cpu().detach().numpy().astype(int)
# If using another model to help centre the bounding boxes (person detection model in this case)
if person_res and len(person_res[0].boxes):
x3,y3,x4,y4 = person_res[0].boxes.xyxy[0].cpu().detach().numpy() .astype(int)
else:
x3,y3,x4,y4 = x1,y1,x2,y2
# Differences in calculating final bounding boxes depending on where the object is in relation to the person
if "top" in product_class:
l = max( max(0, x1-w_pad), max(0, x3-w_pad))
t = min( max(0, y1-h_pad), max(0, y3-h_pad))
r = min( min(w, x2+w_pad), min(w, x4+w_pad))
b = min(h, y2+h_pad)
else:
l = max( max(0, x1-w_pad), max(0, x3-w_pad))
t = max(0, y1-h_pad)
r = min( min(w, x2+w_pad), min(w, x4+w_pad))
b = max( min(h, y2+h_pad), min(h, y4+h_pad))
l, r, t, b = int(l), int(r), int(t), int(b)
cropped_imgs.append(product_img[t:b, l:r])
left_pad = x1-l
right_pad = r-x2
paddings.append((left_pad, right_pad))
product_classes.append(product_class)
return cropped_imgs, paddings, product_classes
def resize_pad(cropped_img, padding=None, target_res=(1270,1750), product_class=''):
# Determine dimensions and directions to pad
h_ratio, w_ratio = target_res[0]/int(cropped_img.shape[0]), target_res[1]/int(cropped_img.shape[1])
extend_direction = h_ratio/w_ratio
# Resized image dimensions needs to have both height and width within the target resolution
target_h_img = target_res[0]
ratio = target_h_img/ int(cropped_img.shape[0])
target_w_img = int(ratio * int(cropped_img.shape[1]))
if target_w_img > target_res[1]:
ratio = target_w_img / target_res[1]
target_w_img = int(int(target_w_img)/ratio)
target_h_img = int(target_h_img/ratio)
img = PIL.Image.fromarray(cropped_img)
img = img.resize((target_w_img, target_h_img), PIL.Image.Resampling.LANCZOS)
resized_image = np.array(img)
# Two new arrays to store resized+padded image and the mask
resized_image = resized_image.transpose(2,0,1).reshape(resized_image.shape[2], resized_image.shape[0], resized_image.shape[1])
img_arr = np.ndarray((3, resized_image.shape[1] + (target_res[0]-target_h_img), resized_image.shape[2] + (target_res[1]-target_w_img)), int)
mask_arr = np.ndarray((3, resized_image.shape[1] + (target_res[0]-target_h_img), resized_image.shape[2] + (target_res[1]-target_w_img)), int)
# Calculations for paddings to apply along each direction to achieve target resolution
pad_l = int((target_res[1] - img.size[0])/2)
pad_r = int(target_res[1] - pad_l - img.size[0])
pad_t = int((target_res[0] - img.size[1])/2)
pad_b = int(target_res[0] - pad_t - img.size[1])
if "top" in product_class:
pad_t = pad_t + pad_b
pad_b = 0
elif "bottom" in product_class:
pad_b = pad_t + pad_b
pad_t = 0
padded_l, padded_r = padding
# extending edges of each colour channel separately
for i, x in enumerate(resized_image):
# obtain median color from padded width from cropping object detection
cons = (int(np.median(x[:,:padded_l])), int(np.median(x[:, -padded_r:])))
# 2 part padding to stagger ramp up
x_p = np.pad(x, ((pad_t//2,pad_b//2),(pad_l//2 , pad_r//2)), 'linear_ramp', end_values=cons)
x_p = np.pad(x_p, ((pad_t-pad_t//2,pad_b-pad_b//2),(pad_l - pad_l//2 , pad_r - pad_r//2)), 'linear_ramp', end_values=cons)
# mask starts from original cropped edge
img_arr[i,:,:] = x_p
mask_arr[i,:pad_t, :pad_l] = 255
mask_arr[i,-pad_b:, -pad_r:] = 255
img_arr = np.uint8(img_arr).transpose(1,2,0)
mask_arr = np.uint8(mask_arr).transpose(1,2,0)
b = cv2.GaussianBlur(img_arr, (5,5), (0))
img_arr = np.array(img_arr)
# apply blur to mask
img_arr[mask_arr>0] = b[mask_arr>0]
img = PIL.Image.fromarray(img_arr)
final_image = img.resize((target_res[1], target_res[0]), PIL.Image.Resampling.LANCZOS)
return np.array(final_image)
test_img_path = 'images/pexels-amina-filkins-5560019.jpg'
top_bottom_classes = list(range(9))
res = detect(model, test_img_path, top_bottom_classes)
cropped_imgs, paddings, product_classes = crop_image(test_img_path, res, person_res=person_res)
# For the following 3 resolutions
target_res_list = [(1080,1920), (1750,1200), (1000,1000)]
for i in range(len(cropped_imgs)):
for target_res in target_res_list:
resized_img_arr = resize_pad(cropped_imgs[i], padding=paddings[i], target_res=target_res, product_class=product_classes[i])
resized_img = PIL.Image.fromarray(resized_img_arr)
print(f"Displaying Image for {product_classes[i]} at {resized_img.size} resolution")
display(resized_img)
Speed: 2.2ms preprocess, 10.5ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 448)
Displaying Image for long_sleeve_top at (1920, 1080) resolution

Displaying Image for long_sleeve_top at (1200, 1750) resolution

Displaying Image for long_sleeve_top at (1000, 1000) resolution

Displaying Image for trousers_bottom at (1920, 1080) resolution

Displaying Image for trousers_bottom at (1200, 1750) resolution

Displaying Image for trousers_bottom at (1000, 1000) resolution

Above we can see that our functions produced separate images that focuses on the top and bottom apparels, centering our subject of interest and extending the background to our desired resolution.
Unfortunately, one flaw that we can easily identify is that the extended background does not always blend seamlessly with our original image, most evident in the last two images for the trousers.
At this point this tool extends the background with the median color along the edges of the original image before applying a gaussian blur to help smooth the colors between the original and extended background. This does not work for certain backgrounds and will result in very obvious lines/artifacts on the final image, possible quick solutions would be to bump up the strength of the blur or account for different colors along different portions of the edges.
However, even with this flaw the tool has done what it was created for marvelously completing what would normally be a few minutes of work in a image editting software within a few seconds.
test_img_path = 'images/pexels-amina-filkins-5560019.jpg'
person_res = detect(person_model, test_img_path, 0)
cropped_imgs, paddings, product_classes = crop_image(test_img_path, person_res)
# For the following 3 resolutions
target_res_list = [(1080,1920), (1750,1200), (1000,1000)]
for i in range(len(cropped_imgs)):
for target_res in target_res_list:
resized_img_arr = resize_pad(cropped_imgs[i], padding=paddings[i], target_res=target_res)
resized_img = PIL.Image.fromarray(resized_img_arr)
print(f"Displaying Image for {product_classes[i]} at {resized_img.size} resolution")
display(resized_img)
Speed: 2.0ms preprocess, 15.0ms inference, 1.5ms postprocess per image at shape (1, 3, 640, 448)
Displaying Image for person at (1920, 1080) resolution

Displaying Image for person at (1200, 1750) resolution

Displaying Image for person at (1000, 1000) resolution

Above we see the images in various resolutions, this time focusing on the entire person instead of specific products within the image.
5. Conclusion
In this notebook we have explored the application of YOLOv8 as an object detection model to efficiently crop and resize images in the context of retail e-commerce images. Limitations and possible solutions have also been identified for future possible enhancements to our tool.
An implementation of this tool as a simple python application can be found in the next notebook.