Gradio Interface for RAG Chatbot
Contents
- Introduction
- Gradio Components
2.1 Chatbot
2.2 Selecting Vectorstore Filepath
2.3 Selecting Vectorstore Collection
2.4 Adding New Documents - Full Interface
- Conclusion
1. Introduction
In a previous notebook we have explored the application of Retrieval Augmented Generation (RAG) with Large Language Models (LLMs) to create powerful chatbots to help users quickly access and digest relevant information within their database of digital content.
Now we will create a simple interface using the Gradio framework for users to interact with the chatbot and maintain their database of reference documents.
2. Gradio Components
First we will create and validate individual components of our chatbot interface. When we have our components ready we will then combine and run them as a single interface.
2.1 Chatbot component
Gradio provides a few different approaches to creating the chatbot component. In this case we will directly use the Chatbot component.
import ollama
import gradio as gr
history = []
messages = []
def send(chat, history):
messages.append(
{
'role':'user',
'content':chat,
}
)
response = ollama.chat(model='dolphin-mistral',
messages = messages
)
messages.append(
{
'role':'assistant',
'content':response['message']['content'],
}
)
history.append([chat, response['message']['content']])
return "", history
After creating the function send that will maintain chat history while handling communications between the user and LLM, we can simply plug this function into our Gradio component as shown below.
with gr.Blocks(title='Test Chatbot',
theme='soft'
) as demo:
chatbot = gr.Chatbot(value=[], elem_id='chatbot', height=400)
with gr.Row():
msg = gr.Textbox(
placeholder="Enter prompt here",
container = False,
scale=3
)
submit_button = gr.Button('Send', scale=1)
clear_button = gr.ClearButton([msg, chatbot], scale=1)
msg.submit(send, [msg, chatbot], [msg, chatbot])
demo.launch()
demo.close()
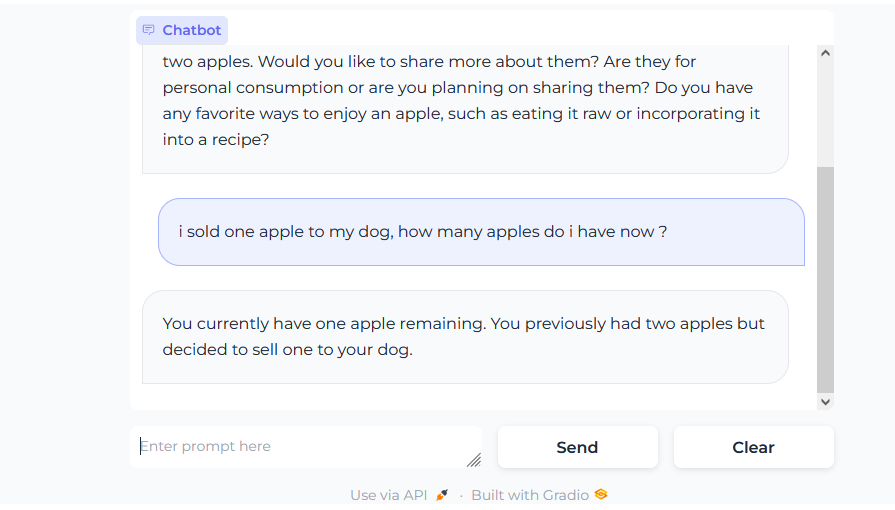
As seen above, our interface works and the model is able to keep track of the number of apples I have, suggesting the the chat history is working as well.
2.2 Vectorstore Filepath component
Next we need to be able to select our vectorstore folder that contains our collections of documents. As I was unable to get folder directory selection working on Gradio directly, we will be include tkinter to help select just a folder path.
Once we have our tkinter function ready we can just plug it into a button on our interface for the user to trigger the filepath selection.
import gradio as gr
import os
from tkinter import Tk, filedialog
def on_browse():
root = Tk()
root.attributes("-topmost", True)
root.withdraw()
filename = filedialog.askdirectory()
if filename:
if os.path.isdir(filename):
root.destroy()
return str(filename)
else:
root.destroy()
return str(filename)
else:
filename = "Folder not selected"
root.destroy()
return str(filename)
with gr.Blocks() as demo:
with gr.Row():
input_path = gr.Textbox(label="Select Vectorstore Directory", scale=5, interactive=True)
image_browse_btn = gr.Button("Browse", min_width=1)
image_browse_btn.click(on_browse, outputs=input_path, show_progress="hidden")
demo.launch()
demo.close()
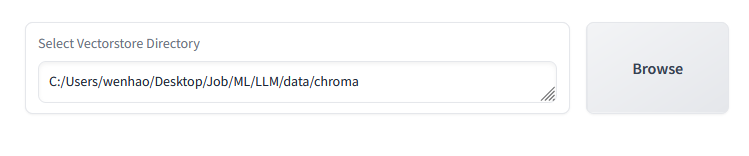
As tested above, our filepath selection component is working as intended!
2.3 Vectorstore Collections component
We can select our vectorstore, now it’s time to select our collections. As a refresher, collections are the grouping mechanism for our documents within our ChromaDB vectorstore.
For testing purposes, we shall use a vectorstore that has been prepared beforehand.
import chromadb
folder_path = 'app/data'
chroma_client = chromadb.PersistentClient(path=folder_path+'/chroma')
collection_names = [c.name for c in chroma_client.list_collections()]
collection_names
['statistics', 'baby_names', 'aiml', 'valve', 'programming']
With the chroma client loaded up and collection names extracted, we can create and place a function to select our collection within a dropdown field on our interface.
def select_collection(textbox, coll):
textbox = gr.Textbox(label="Selected Collection: ", value=coll)
return textbox
with gr.Blocks() as demo:
dropdown = gr.Dropdown(sorted(collection_names), label="Documents", info="Select a documents for LLM to reference")
# Sanity check
text = gr.Textbox(label="Sanity Check: ", value="")
text = dropdown.change(select_collection, inputs=[text, dropdown], outputs=text)
demo.launch()
demo.close()
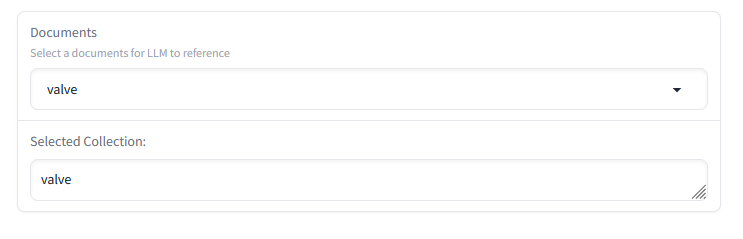
In the above interface I have included a textbox as a sanity check. This textbox will update whenever our selected collection is updated. As we can see they are the same values, this component appears to work as intended.
2.4 Add New Document component
In our final component we will be uploading new documents to our vectorstore. There will be two ways to add new documents through this interface:
- Upload file from disk
- Download webpage as file
On the interface we will have a radio button to control which approach the user wants to use, and the corresponding component will present itself based on the radio button seelction.
import gradio as gr
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
def show_url(textbox, url_input):
textbox = gr.Textbox(label="Sanity Check: ", value=url_input)
return textbox
with gr.Blocks() as demo:
# Radio options
data_type = gr.Radio(choices=["Files", "URL"], value="Files", label="Document source")
with gr.Column():
# File uploader
with gr.Row(visible=True) as fileRow:
file_output = gr.File(label="Upload File")
upload_button = gr.UploadButton("Click to Upload a File", file_count="multiple")
upload_button.upload(upload_file, upload_button, file_output)
# Url provider
with gr.Row(visible=False) as urlRow:
url_input = gr.Textbox(label='Document Url')
send_button = gr.Button('Send')
# Sanity check
text = gr.Textbox(label="Sanity Check: ", value="")
text = send_button.click(show_url, inputs=[text, url_input], outputs=text)
# Toggle visibility of file/url based on radio button
def update_visibility(radio):
if radio == "Files":
return [gr.update(visible=True), gr.update(visible=False)]
elif radio == "URL":
return [gr.update(visible=False), gr.update(visible=True)]
data_type.change(update_visibility, data_type, [fileRow, urlRow])
demo.launch()
demo.close()

Above we see the component for adding files from disk has successfully processed our selected file.
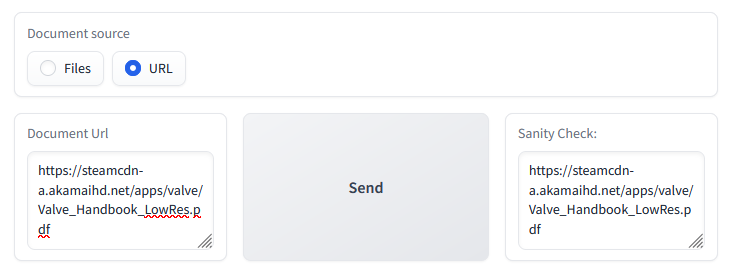
Here we see the component for adding a file from a webpage has successfully processed the provided url. As a sanity check I have included a textbox that will update itself when our url has been successfully input.
With this we have created our individual components and can move onto combining them with our chatbot/database logic to create our final interface!
3. Full Interface
To implement the full interface, the backend RAG/LLM logic is implemented within a separate class LLM and will not be the main focus of this notebook.
Below we see helper functions that were used to implement the individual components we saw earlier. A new function refresh_dropdown is included here. When called, this function will help to refresh the dropdown menu with the collections of the currently loaded vectorstore.
# Select vectorstore file directory
def on_browse():
root = Tk()
root.attributes("-topmost", True)
root.withdraw()
filename = filedialog.askdirectory()
if filename:
if os.path.isdir(filename):
root.destroy()
return str(filename)
else:
root.destroy()
return str(filename)
else:
filename = "Folder not selected"
root.destroy()
return str(filename)
# Select collection
def select_collection(textbox, coll):
textbox = gr.Textbox(label="Selected Collection: ", value=coll)
return textbox
# Send prompt to LLM
def send(chat, history):
results = llm.search_vectorstore(chat)
prompt = llm.create_template_prompt(results, chat)
messages.append(
{
'role':'user',
'content':prompt,
}
)
response = ollama.chat(model='dolphin-mistral',
messages = messages
)
messages.append(
{
'role':'assistant',
'content':response['message']['content'],
}
)
history.append([chat, response['message']['content']])
return "", history
# Upload files of desired documents
def upload_file(files):
file_paths = [file.name for file in files]
return file_paths
# Send url to desired document
def show_url(textbox, url_input):
textbox = gr.Textbox(label="Sanity Check: ", value=url_input)
return textbox
# Refresh dropdown
def refresh_dropdown():
dropdown = gr.Dropdown(llm.COLLECTION_NAMES, label="Collections", info="Select a collection for LLM to reference")
return dropdown
Below is the LLM class that I have created separately. This will control all the backend logic to process and maintain the chatting/RAG capabilities.
import ollama
import gradio as gr
import os
import shutil
import argparse
from tkinter import Tk, filedialog
from tqdm import tqdm
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import BSHTMLLoader
from langchain_community.document_loaders import JSONLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import PyPDFLoader, OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.schema import Document
import chromadb
class LLM:
def __init__(self, data_path='data/', llm_model='dolphin-mistral'):
self.DATA_PATH=data_path
self.RAW_DATA_PATH=self.DATA_PATH +'/raw'
self.MODEL=llm_model
self.PARSER = argparse.ArgumentParser()
self.EMBEDDING_FUNCTION = GPT4AllEmbeddings()
self.COLLECTION_NAME = ''
self.VECTORSTORE = None
self.LOADERS = {
'.csv': CSVLoader,
'.txt': TextLoader,
'.html': BSHTMLLoader,
'.json': JSONLoader,
'.md': UnstructuredMarkdownLoader,
'.pdf': PyPDFLoader
}
self.CHROMA_CLIENT = chromadb.PersistentClient(path=self.DATA_PATH + '/chroma')
self.COLLECTION_NAMES = [c.name for c in self.CHROMA_CLIENT.list_collections()]
self.SYSTEM_PROMPT = ''
def gather_docs(self):
extensions = set(self.LOADERS.keys())
path = Path(self.RAW_DATA_PATH)
p_list = []
for p in path.rglob("*"):
if p.is_file() and p.suffix in extensions:
p_list.append(p)
return p_list, path
def process_docs(self, p_list, path):
with tqdm(total=len(p_list), desc='Process Documents') as pbar:
for p in p_list:
# Get collection from ChromaDB
collection_name = str(p.absolute()).replace(str(path.absolute()), '').split('\\')[1]
collection = self.CHROMA_CLIENT.get_or_create_collection(collection_name)
self.set_collection(collection_name)
# Process file
self.process_single_doc(p)
pbar.update(1)
self.COLLECTION_NAMES = [c.name for c in self.CHROMA_CLIENT.list_collections()]
def process_single_doc(self, p):
# Process and add file to vectorstore
loader = self.LOADERS[str(p.suffix)](p)
raw_docs = loader.load()
if raw_docs:
chunks = self.split_text(raw_docs)
for i in range(len(chunks)):
chunks[i].metadata['source'] = chunks[i].metadata['source'].split('\\')[-1]
self.VECTORSTORE.add_documents(chunks)
# Move processed file to archive folder
destination_path = '\\'.join(str(p.absolute()).replace('raw','archive').split('\\')[:-1])
os.makedirs(destination_path, exist_ok=True)
dest = shutil.move(str(p.absolute()), destination_path)
print(f'Moved {str(p)} to archive.')
def split_text(self, documents: list[Document]):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
add_start_index=True
)
chunks = text_splitter.split_documents(documents)
print(f'Split {len(documents)} documents into {len(chunks)} chunks.')
print(chunks[0].metadata)
return chunks
def save_to_chroma(self, file_name, chunks: list[Document]):
file_path = self.DATA_PATH + str(file_name)
# Remove old file
if os.path.exists(file_path):
shutil.rmtree(file_path)
# Create new file
vectorstore = Chroma.from_documents(
chunks, GPT4AllEmbeddings(), persist_directory=file_path
)
#vectorstore.persist()
print(f'Saved {len(chunks)} chunks to {file_path}')
def load_pdf_url(self, url):
loader = OnlinePDFLoader(url)
documents = loader.load()
return documents
def generate_multiple_data_store(self, urls, collection_name=""):
print(urls)
for url in urls:
print(url)
self.generate_data_store_pdf_url(url, collection_name)
def generate_data_store_pdf_url(self, url, collection_name=""):
if "http" in url:
documents = self.load_pdf_url(url)
source_name = url.split('/')[-1]
else:
loader = self.LOADERS['.' + str(url).split('.')[-1]](url)
documents = loader.load()
source_name = url.split('\\')[-1]
chunks = self.split_text(documents)
for i in range(len(chunks)):
chunks[i].metadata['source'] = source_name
if collection_name:
collection = self.CHROMA_CLIENT.get_or_create_collection(collection_name)
self.set_collection(collection_name)
self.VECTORSTORE.add_documents(chunks)
def get_input(self):
query_text = str(input())
return query_text
def load_vectorstore(self):
vectorstore = Chroma(
client=self.CHROMA_CLIENT,
collection_name=self.COLLECTION_NAME,
embedding_function=self.EMBEDDING_FUNCTION
)
self.VECTORSTORE = vectorstore
def search_vectorstore(self, query_text, k=4):
results = self.VECTORSTORE.similarity_search_with_relevance_scores(query_text, k=4)
return results
def set_collection(self, collection_name):
self.COLLECTION_NAME = str(collection_name)
self.load_vectorstore()
print(f'Vectorstore loaded from {self.COLLECTION_NAME}')
def create_context(self, vectorstore_results):
context_text = "\n---\n".join([doc.page_content for doc, _score in vectorstore_results])
return context_text
def create_template_prompt(self, results, query_text):
context_text = self.create_context(results)
prompt = f"""Answer the question using the following context:
{context_text}
---
Answer the question based on the above context: {query_text}
"""
return prompt
def context_chat(self, query_text, file_name=None, k=4):
# if context file name provided, recreate vectorstore
if file_name:
self.set_collection(self, file_name)
self.load_vectorstore()
# find relevant results
if self.COLLECTION_NAME:
results = self.search_vectorstore(query_text, k)
if len(results) == 0:
output = f"""
============================================
Unable to find matching results from context, producing results without using references
============================================\n
"""
prompt = query_text
elif results[0][1] < 0.5:
output = f"""
============================================
Unable to find good matching results, highest similarity score found is {results[0][1]} from {results[0][0].metadata.get('source', None)}. Producing results using poor references.
============================================\n
"""
prompt = self.create_template_prompt(results, query_text)
else:
prompt = self.create_template_prompt(results, query_text)
sources_str = ''.join([f"Source: {source.metadata.get('source', None)} , Significance: {_score}\n" for source, _score in results])
output = f""""
============================================
{sources_str}
============================================\n
"""
# so function can evaluate the significance of the results and draft prompt and response as required
# concat notification strings w/ output response in case no significant results were found from the vectorstore
if self.SYSTEM_PROMPT:
prompt = self.SYSTEM_PROMPT + '\n' + prompt
response = ollama.chat(model=self.MODEL, messages=[
{
"role": "user",
"content": prompt
}
])
output += response['message']['content']
else:
output = ''
if self.SYSTEM_PROMPT:
prompt = self.SYSTEM_PROMPT + '\n' + query_text
response = ollama.chat(model=self.MODEL, messages=[
{
"role": "user",
"content": query_text
}
])
output += response['message']['content']
return output
def update_chroma_client(self, new_path):
self.CHROMA_CLIENT = chromadb.PersistentClient(path=new_path)
self.COLLECTION_NAMES = [c.name for c in self.CHROMA_CLIENT.list_collections()]
print(self.COLLECTION_NAMES)
And finally, below we will combine all the different components into a single Gradio interface
sanity_checks = 0
llm = LLM()
history = [] # in case we want to restore past conversations
messages = []
# Main Block
with gr.Blocks() as demo:
with gr.Tab("Document Settings"):
# Vectorstore File Directory
with gr.Row():
#data_type = gr.Radio(choices=["Files", "Folder"], value="Files", label="Offline data type")
input_path = gr.Textbox(label="Select Vectorstore Directory", scale=5, interactive=True)
image_browse_btn = gr.Button("Browse", min_width=1)
image_browse_btn.click(on_browse, outputs=input_path).success(llm.update_chroma_client, inputs=[input_path])
# Update dropdown list of collections
def update_dropdown():
print(llm.COLLECTION_NAMES)
return gr.update(choices=llm.COLLECTION_NAMES)
# Vectorstore List Collections
with gr.Row():
dropdown = gr.Dropdown(llm.COLLECTION_NAMES, label="Collections", info="Select a collection for LLM to reference")
# Sanity check
if sanity_checks:
text = gr.Textbox(label="Sanity Check: ", value="")
text = dropdown.change(select_collection, inputs=[text, dropdown], outputs=[text])
refresh_dropdown_button = gr.Button('Refresh')
refresh_dropdown_button.click(llm.update_chroma_client, inputs=[input_path]).success(update_dropdown, outputs=[dropdown])
dropdown.change(llm.set_collection, inputs=[dropdown])
# Add New Document to Vectorstore
with gr.Accordion("Add new documents to vectorstore", open=False):
# Radio options
data_type = gr.Radio(choices=["Files", "URL"], value="Files", label="Document source")
collection_name = gr.Textbox(label='Collection name for document')
with gr.Column():
# File uploader
with gr.Row(visible=True) as fileRow:
file_output = gr.Files(label="Upload File")
process_document_button = gr.Button('Process Documents')
process_document_button.click(llm.generate_multiple_data_store, inputs=[file_output, collection_name])
# Url provider
with gr.Row(visible=False) as urlRow:
url_input = gr.Textbox(label='Document Url')
send_button = gr.Button('Send')
process_webpage_button = gr.Button('Process Webpage')
process_webpage_button.click(llm.generate_data_store_pdf_url, inputs=[url_input, collection_name])
# Sanity check
if sanity_checks:
text = gr.Textbox(label="Sanity Check: ", value="")
text = send_button.click(show_url, inputs=[text, url_input], outputs=text)
# Toggle visibility of file/url based on radio button
def update_visibility(radio):
if radio == "Files":
return [gr.update(visible=True), gr.update(visible=False)]
elif radio == "URL":
return [gr.update(visible=False), gr.update(visible=True)]
data_type.change(update_visibility, data_type, [fileRow, urlRow])
# Chatbot
with gr.Tab("ChatBot"):
chatbot = gr.Chatbot(value=[], elem_id='chatbot', height=300)
with gr.Row():
msg = gr.Textbox(
placeholder="Enter prompt here",
container = False,
scale=3
)
submit_button = gr.Button('Send', scale=1)
clear_button = gr.ClearButton([msg, chatbot], scale=1)
msg.submit(send, [msg, chatbot], [msg, chatbot])
demo.launch()
demo.close()
Our final interface is split into two tabs, one for managing our documents and another for interacting with the chatbot.
1. Documents
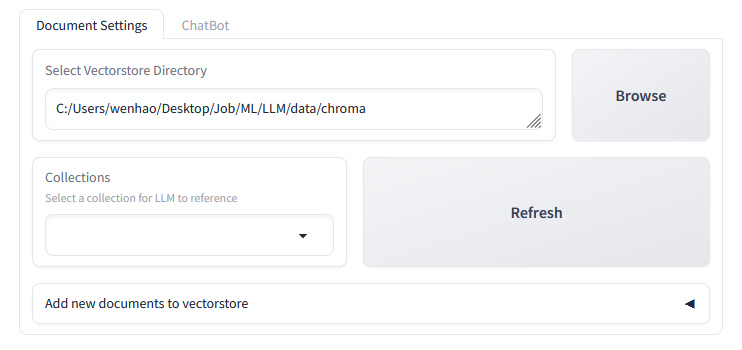
Above we see the interface to manage our documents, where we can select the file directory for our vectorstore, select the collections from our vectorstore, or add new documents to our vectorstore.
We see that our test vectorstore has already been selected in the first field.
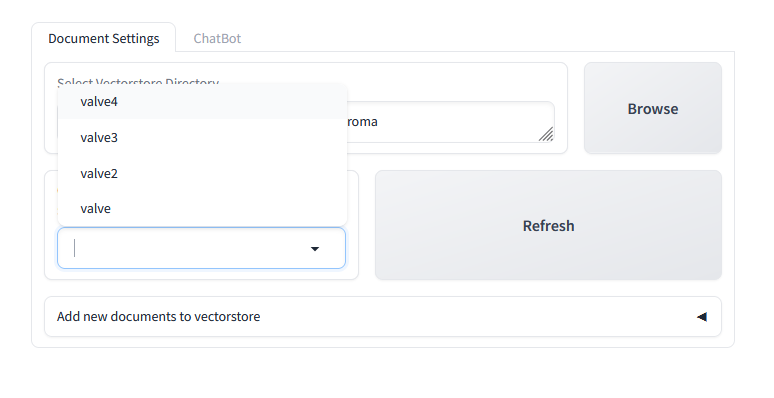
Within this vectorstore, we see 4 different collections of documents already present under their various names.
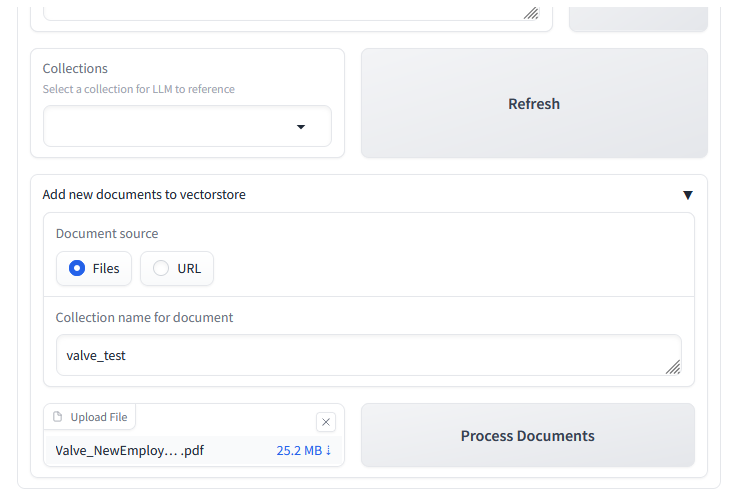
Next we shall try uploading a document under a new collection name valve_test.
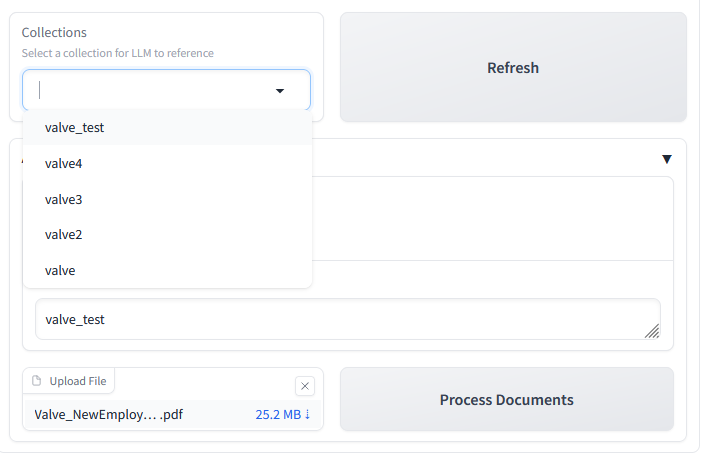
Refreshing the field after the upload completes successfully shows that our collection has been created successfully!
With the new collection selected, we shall move onto the next tab and test out the RAG feature of our chatbot.
2. Chatbot
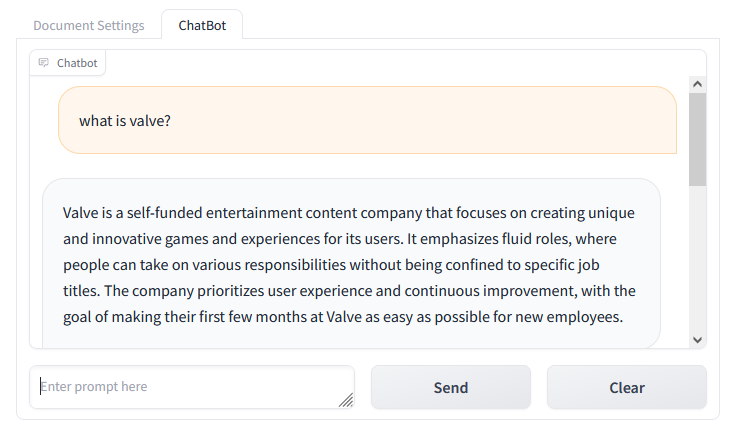
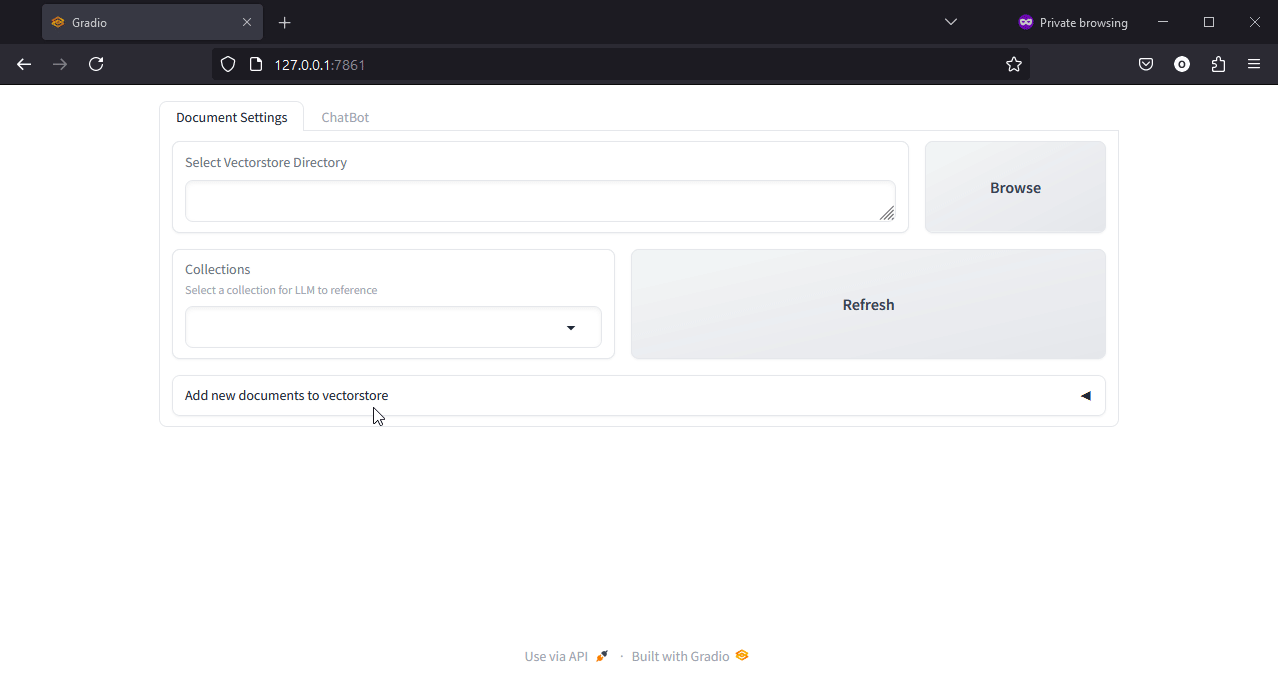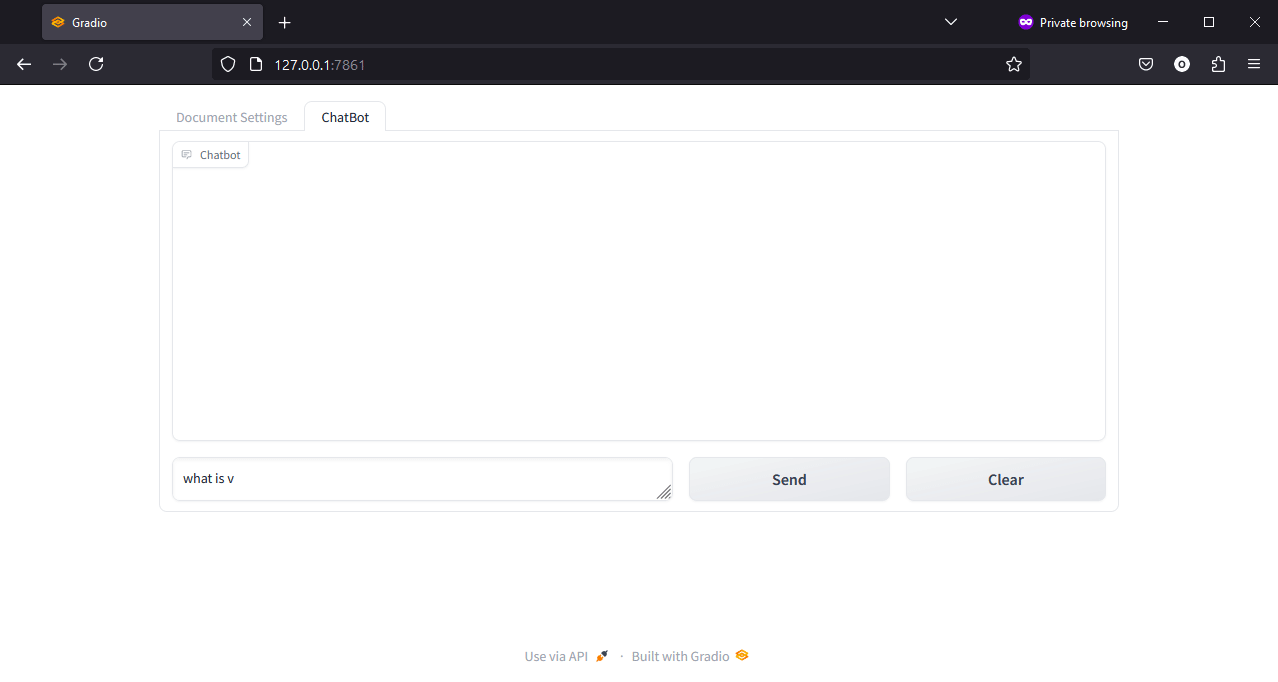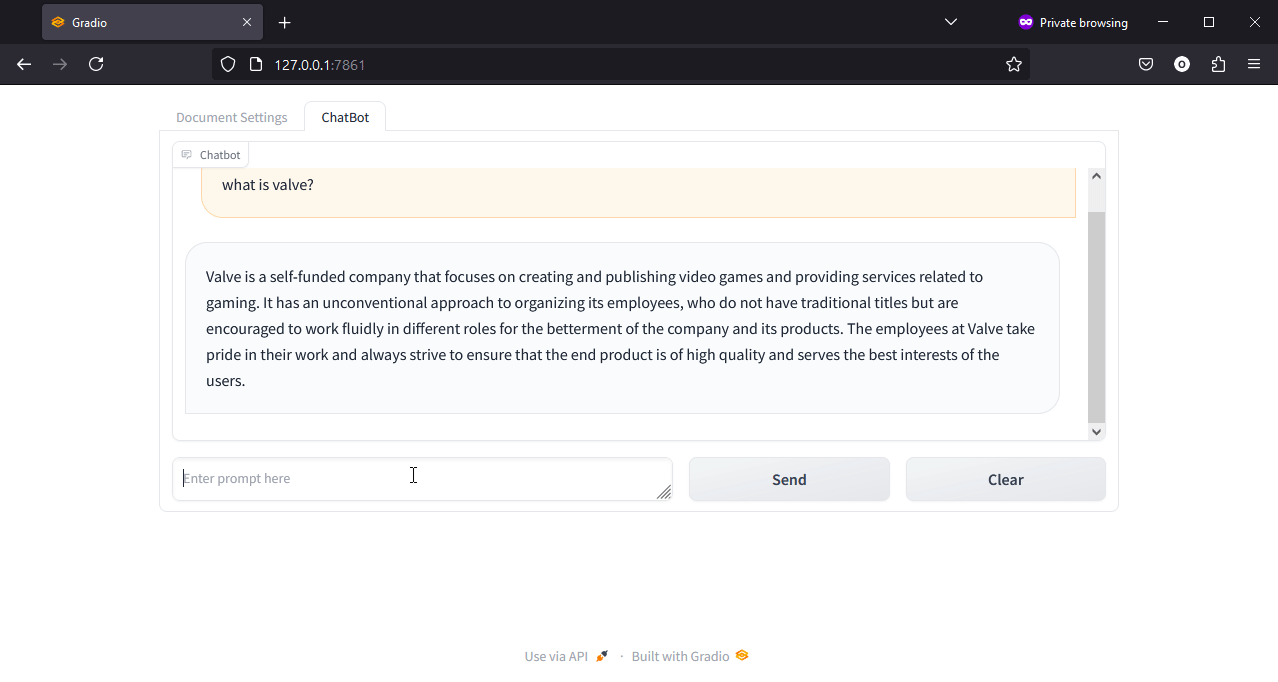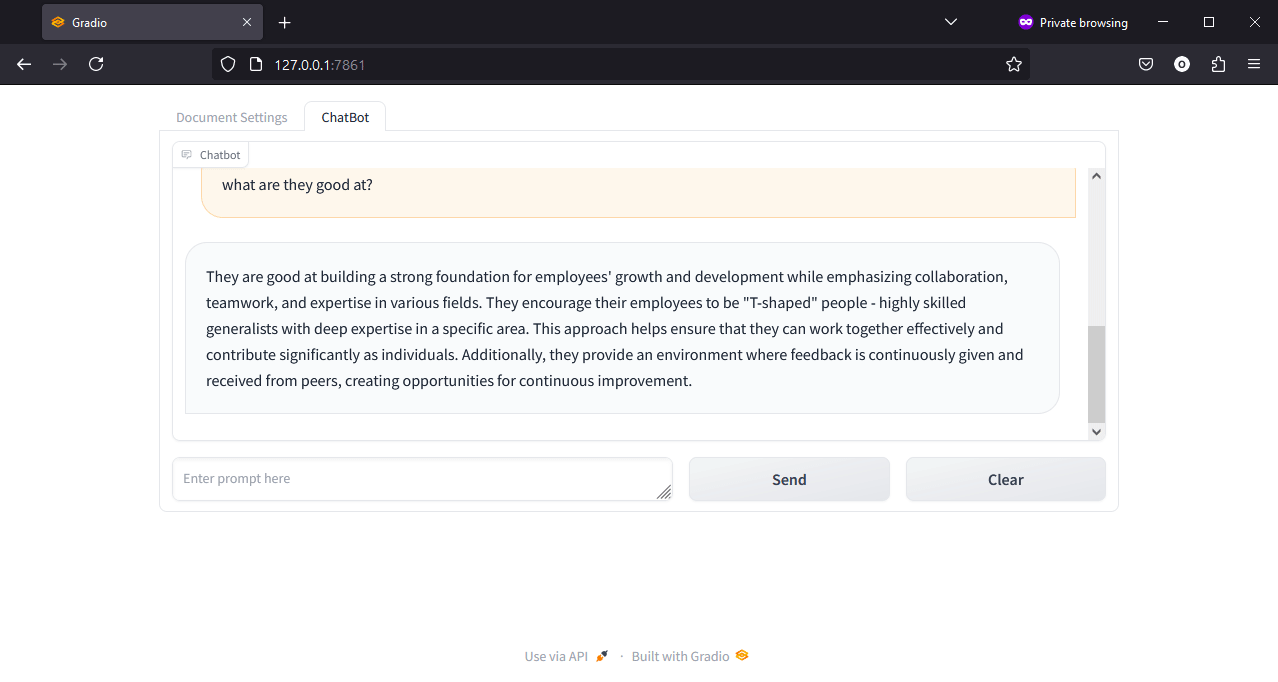
Asking our chatbot what is valve? the chatbot has provided a response using parts of our collection as additional context.
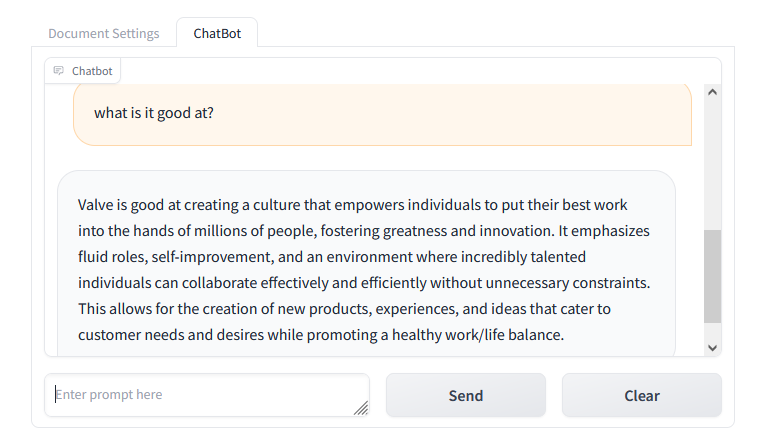
Asking a follow up question what is it good at?, again the chatbot provided a response using our collection as additional context, while also successfully inferring that it within our prompt is referring to Valve that we were asking about in our first question.
4. Conclusion
In this notebook we explored using the Gradio framework to quickly create an interface for users to interact with our chatbot, successfully implementing both RAG and LLM components in the interface allowing users to manage and utilize a simple RAG chatbot within their browser.