Improving Large Language Models (LLMs) Through Retrievel Augmented Generation (RAG)

Contents
1. Introduction
LLMs have become one of the most promising areas in deep learning research over the past few years. These powerful models are trained on vast amounts of text data, enabling them to generate human-like text and the ability to work with complex natural language queries. However, an LLMs ability and responses are largely dependent on the quality and quantity of the training data, limiting their abilities to respond to queries requiring recent or very specific knowledge. In many cases the model may “hallucinate” and generate convincing responses that are completely incorrect, providing users with wrong information.
In this notebook we will explore running an LLM locally, as well as how our model can utilize RAG to alleviate problems of hallucination and knowledge gaps in the training data. If the results are of a reasonably high quality I plan to implement a RAG-based LLM into a Telegram chatbot to help users quickly access and digest relevant information within their database of digital content.
2. Local LLM - Ollama
We will be using the ollama python library as well as running a local ollama server. The local machine used contains an RTX 3070 and 32GB of RAM, which was taken into consideration when choosing the LLMs that we use.
For demonstration we will be using the 7B parameters version of dolphin-mistral, which looking at benchmarks should fit into our RAM comfortably, with a reasonably quick inference time as well.
import ollama
import os
response = ollama.chat(model='dolphin-mistral', messages=[
{
'role': 'user',
'content': 'Please suggest 10 short creative github repository names for my Python chat bot that will make use of LLM and the messaging platform Telegram, the bots main purpose is to help users with interview preparation and content summarization.',
}
])
print(f"Time taken to generate response: {response['eval_duration'] / 10 ** 9 :.3f}s")
Time taken to generate response: 3.937s
print(response['message']['content'])
Here are some creative GitHub repository names for your Python chatbot:
1. PoseidonPython - Inspired by Poseidon, the god of the sea in Greek mythology, this chatbot helps users navigate through the depths of their interview preparation.
2. ApolloAssistant - Named after Apollo, the ancient Greek god of light and knowledge, this bot will enlighten users on their interview preparation journey.
3. MedusaMemo - Influenced by the mythical creature Medusa, this chatbot helps you tame your thoughts and summarize important content for interviews.
4. PrometheusPrep - Named after the Titan who brought fire to mankind, this bot will help users ignite their interview preparation with powerful insights.
5. PygmalionPreparedness - Inspired by Pygmalion, the mythical sculptor who brought his statue to life, this chatbot helps users bring their interview skills to life.
6. DaedalusDistiller - Named after the legendary inventor and creator of the Labyrinth in Greek mythology, this bot will help users find their way through content summarization with ease.
7. OrpheusOutline - Inspired by the ancient Greek poet Orpheus, this chatbot helps users create beautiful outlines for their interview preparation.
8. HephaestusHelper - Named after Hephaestus, the ancient Greek god of craftsmen and blacksmiths, this bot will help users forge their way through effective interview preparation.
9. PyrrhusPrepper - Inspired by King Pyrrhus of Epirus, known for his great military victories, this chatbot helps users conquer their interview preparation with precision.
10. HeraHighlights - Named after the ancient Greek queen and goddess Hera, this bot will help users hone in on the most important highlights for their interview preparation.
Requesting the model to suggest 10 short creative github repository names for the chat bot we see that inference took less than 4 seconds, and the model was inspired by Greek mythology in its response.
Next, let’s look at a simple example of prompt engineering that does not require any technical knowledge. We shall simply request for a simple recipe of a pasta dish, with measurements details for 2 servings. The twist here is that we will add in another line within our query asking the response to be written in a style of an elderly wizard who is having a backache.
response = ollama.chat(model='dolphin-mistral', messages=[
{
'role': 'user',
'content': """In a style of an elderly wizard who is having a backache
Tell me a simple recipe for your favorite pasta dish with measurements for 2 servings""",
}
])
print(f"Time taken to generate response: {response['eval_duration'] / 10 ** 9 :.3f}s")
Time taken to generate response: 7.396s
print(response['message']['content'])
Ah, young one, I see you seek a remedy for the discomfort that befalls us all in our old age. Alas, I fear my wisdom lies more in the realm of magic and lore than it does in the art of culinary delights. However, I can guide you through the creation of a pasta dish that is both simple and scrumptious.
Gather your ingredients:
- 8 oz (227 g) of your favorite pasta, such as spaghetti or fettuccine
- 1 tablespoon (15 ml) of olive oil
- 2 cloves of garlic, minced
- 1 can (14.5 oz/411 g) of diced tomatoes with their juices
- 1/2 cup (120 ml) of heavy cream or half-and-half
- 1/2 cup (50 g) of grated Parmesan cheese, plus more for serving
- Salt and freshly ground black pepper, to taste
- Fresh basil leaves, chopped, for garnish
Now, heed my words, young one:
1. Boil the water in a large pot over high heat. Add a generous pinch of salt and stir in the pasta. Cook the pasta according to package instructions until it is al dente - tender but still firm to the bite. Drain the pasta, reserving about 1/2 cup (120 ml) of the cooking water.
2. While the pasta cooks, prepare the sauce in a large skillet over medium heat. Add the olive oil and swirl it around until it's warm but not smoking. Then, toss in your minced garlic and sauté it gently for about 30 seconds, or until it becomes fragrant but not browned.
3. Pour the canned tomatoes and their juices into the skillet with the garlic and olive oil. Season this mixture with a pinch of salt and black pepper, to taste. Allow this simmering concoction to cook for about 5 minutes, or until the sauce has thickened slightly.
4. Once your sauce is ready, stir in the heavy cream (or half-and-half) and allow it to warm through for a minute or two. Then, gently mix in the grated Parmesan cheese, stirring continuously until it has melted into the sauce.
5. Fold the cooked pasta into the sauce, ensuring that each strand is evenly coated. If you find that your sauce is too thick, you can add a little bit of the reserved pasta cooking water to thin it out. Adjust the seasoning with salt and pepper, if needed.
6. Serve your scrumptious creation in bowls, garnishing each portion with freshly chopped basil leaves and a sprinkling of additional grated Parmesan cheese.
And there you have it! A delightful pasta dish fit for any feast or simple meal. Remember to savor every bite - after all, the magic is in the moments we share around our tables.
This time inference took slightly longer at 7.4s, but we see that the response indeed reads like an elderly wizard passing down his pasta recipe! This is a sneak peek at what sort of control we have over the models generated response, and will be one of the main components of RAG in the next section.
3. Retrieval Augmented Generation (RAG)
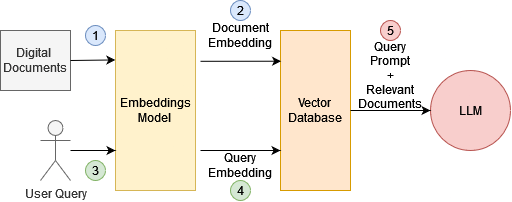
- Digital documents are processed and embedded into vectors.
- Embeddings of these documents are stored in vector databases, along with relevant metadata as required.
- A user sends a query in a form of a prompt to some LLM API.
- The query gets embedded into vectors and sent to the vector database to search for relevant document embeddings using some form of similarity search.
- The relevant document embeddings are transformed back into natural language and combined with the original user prompt, providing context to the LLM for reference when responding to the user prompt.
For exploration purposes we will use Valve’s Employee Handbook pdf file to walk through the embedding and prompting process.
We will be using LangChain framework to help simplify the entire process.
For our vector database we will be using Chroma.
from langchain_community.document_loaders import OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain_community.vectorstores.chroma import Chroma
from langchain.schema import Document
import os
CHROMA_PATH = 'chroma'
pdf_url = "https://steamcdn-a.akamaihd.net/apps/valve/Valve_NewEmployeeHandbook.pdf"
embedding_function = GPT4AllEmbeddings()
def generate_data_store_pdf_url(url):
documents = load_pdf_url(url)
chunks = split_text(documents)
save_to_chroma(chunks)
def load_pdf_url(url):
loader = OnlinePDFLoader(url)
documents = loader.load()
return documents
def split_text(documents: list[Document]):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
add_start_index=True
)
chunks = text_splitter.split_documents(documents)
print(f'Split {len(documents)} documents into {len(chunks)} chunks.')
return chunks
def save_to_chroma(chunks: list[Document], file_path='chroma'):
# Check if vectorstore already exists
if os.path.exists(file_path):
shutil.rmtree(file_path)
print(f"Vectorstore for {chunks[0].metadata['source']} already exists")
return
# Create new file
vectorstore = Chroma.from_documents(
chunks, embedding_function, persist_directory=file_path
)
print(f'Saved {len(chunks)} chunks to {file_path}.')
The above code processes the pdf file from our url, then splits it into chunks before saving their embeddings in a vector database under the file path /chroma.
generate_data_store_pdf_url(pdf_url)
Split 1 documents into 77 chunks.
Saved 77 chunks to chroma.
We see that the pdf was save as 77 different chunks.
import argparse
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain.prompts import ChatPromptTemplate
import ollama
CHROMA_PATH = 'chroma'
llm_model = 'dolphin-mistral'
# Our user prompt
query_text = 'what is valve?'
# Prepare vectorstore
embedding_function = GPT4AllEmbeddings()
vectorstore = Chroma(persist_directory=CHROMA_PATH, embedding_function=embedding_function)
# Search vectorstore for top k most relevant chunks
results = vectorstore.similarity_search_with_relevance_scores(query_text, k=4)
if results[0][1] < 0.2 :
print(f'Unable to find good matching results, highest similarity score found is {results[0][1]}')
context_text = "\n---\n".join([doc.page_content for doc, _score in results])
# Prompt with rag
prompt_rag = f"""Answer the question using the following context:
{context_text}
---
Answer the question based on the above context: {query_text}"""
response_rag = ollama.generate(llm_model, prompt_rag)
output_rag = response_rag['response']
print(f"Time taken to generate response with RAG: {response_rag['eval_duration'] / 10 ** 9 :.3f}s \n")
print(output_rag)
print('\n******************************************\n')
# Prompt without rag
response = ollama.generate(llm_model, query_text)
output = response['response']
print(f"Time taken to generate response without RAG: {response['eval_duration'] / 10 ** 9 :.3f}s \n")
print(output)
Time taken to generate response with RAG: 2.122s
Valve is a game company and more, founded in 1996 with the goal of fostering greatness through a place that empowers incredibly talented individuals to put their best work into the hands of millions of people. It is self-funded and owns its intellectual property, which allows for making decisions about its products freely. The company has expanded its focus beyond traditional game development to include various other areas as well. Valve provides an opportunity for extremely efficient and accelerated career growth through broadening one's skill set outside of narrow career constraints.
******************************************
Time taken to generate response without RAG: 4.493s
A valve is a device designed to control the flow of fluids (liquid or gases) by opening, closing, or partially obstructing various passageways. Valves are used in a wide range of applications and industries, including plumbing systems, automotive systems, hydraulic systems, pneumatic systems, and chemical processing plants.
Valves can be classified according to several criteria:
1. Type of service: Regulating, non-return, control, safety, isolation, relief, pressure reducing, flow controlling, and throttling valves are some examples.
2. Design: Gate, globe, butterfly, plug, ball, diaphragm, and check valves are the most common types of valve designs.
3. Operation: Manual or automatic valves can be operated by hand, pneumatically, electrically, hydraulically, or through other means.
4. Material: Valves can be made from different materials such as metal (stainless steel, brass, iron), plastics (PVC, PP, PVDF), rubber, PTFE, or composite materials depending on the application requirements and environment in which they will be used.
Above we have searched for the chunks of documents from the vector database that are most relevant to the query_text and included these chunks into our LLM prompt as additional context. The LLM then processes the prompts and tries to generate a response with reference to these additional context.
In our RAG response we see that the model has answered our question "what is valve?" with reference to the original pdf document we have provided.
In our response without RAG the model has provided answers to the valve device instead of the company, completely missing the context of our question. In this scenario as Valve is a popular company that has been around for decades I am confident that even without RAG the model would be able to provide a satifactory answer with a proper prompt like "What is the company Valve?", but this example illustrates how RAG can be used to alleviate these contextual issues.
The above implementation is limited to processing PDF files and 1 file per vectorstore, but in reality we would be interested in creating a large database to store our references of different file formats. Hence we shal improve the above implementation to cover some file formats that I work with frequently.
import os
import shutil
from tqdm import tqdm
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import BSHTMLLoader
from langchain_community.document_loaders import JSONLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores.chroma import Chroma
from langchain_community.embeddings import GPT4AllEmbeddings
from langchain_community.document_loaders.generic import GenericLoader
import chromadb
import ollama
loaders = {
'.csv': CSVLoader,
'.txt': TextLoader,
'.html': BSHTMLLoader,
'.json': JSONLoader,
'.md': UnstructuredMarkdownLoader,
'.pdf': PyPDFLoader
}
In the above code I have defined file format-specific loaders to help parse and process documents of different formats as required.
folder_path = 'app/data'
raw_doc_path = folder_path +'/raw'
embedding_function = GPT4AllEmbeddings()
chroma_client = chromadb.PersistentClient(path=folder_path+'/chroma')
extensions = set(loaders.keys())
path = Path(raw_doc_path)
# Gather list of files to process
p_list = []
for p in path.rglob("*"):
if p.is_file() and p.suffix in extensions:
p_list.append(p)
# Process list of files:
with tqdm(total=len(p_list), desc="Process Documents") as pbar:
for p in p_list:
# Get collection from ChromaDB
print(str(p.absolute()).replace(str(path.absolute()),'').split('\\')[1])
collection_name = str(p.absolute()).replace(str(path.absolute()),'').split('\\')[1]
collection = chroma_client.get_or_create_collection(collection_name)
# Get ChromaDB collection in langchain
langchain_chroma = Chroma(
client=chroma_client,
collection_name=collection_name,
embedding_function=embedding_function,
)
# Process file
loader = loaders[str(p.suffix)](p,)
raw_docs = loader.load()
if raw_docs:
chunks = split_text(raw_docs)
for i in range(len(chunks)):
chunks[i].metadata['source'] = chunks[i].metadata['source'].split('\\')[-1]
langchain_chroma.add_documents(chunks)
# Move processed file to archive folder
destination_path = '\\'.join(str(p.absolute()).replace('raw','archive').split('\\')[:-1])
os.makedirs(destination_path, exist_ok=True)
dest = shutil.move(str(p.absolute()), destination_path)
print(f'Moved {str(p)} to archive.')
pbar.update(1)
In my disk I have placed some documents within the file path /app/data/raw within subfolders of their respective categories. The code will create 1 vector database within /app/data/chroma, along with a collection for each category of documents.
In Chroma collections are the grouping mechanism for embeddings, documents, and metadata. This will allow us to pass collection names to perform our similarity search on instead of searching through the entire database each time a prompt is parsed.
for col in chroma_client.list_collections():
print(f"Number of docs in Collection {col.name} : {len(chroma_client.get_collection(col.name).get()['metadatas'])}")
Number of docs in Collection statistics : 2513
Number of docs in Collection baby_names : 26355
Number of docs in Collection aiml : 14713
Number of docs in Collection valve : 82
Number of docs in Collection programming : 10469
We see that 5 different collections are stored in our vector database along with their respective number of chunks.
Similar to what we did with the entire vectorstore before, now query a specific collection for our relevant context instead.
import chromadb
# Load chroma database and collection
folder_path = 'app/data'
chroma_client = chromadb.PersistentClient(path=folder_path+'/chroma')
vectorstore = Chroma(
client=chroma_client,
collection_name="valve",
embedding_function=embedding_function
)
# Our user prompt
query_text = 'what is valve?'
# Search vectorstore for top k most relevant chunks
results = vectorstore.similarity_search_with_relevance_scores(query_text, k=4)
if results[0][1] < 0.2 :
print(f'Unable to find good matching results, highest similarity score found is {results[0][1]}')
context_text = "\n---\n".join([doc.page_content for doc, _score in results])
# Prompt with rag
prompt_rag = f"""Answer the question using the following context:
{context_text}
---
Answer the question based on the above context: {query_text}"""
response_rag = ollama.generate(llm_model, prompt_rag)
output_rag = response_rag['response']
print(f"Time taken to generate response with RAG: {response_rag['eval_duration'] / 10 ** 9 :.3f}s \n")
print(output_rag)
print('\n******************************************\n')
Time taken to generate response with RAG: 1.821s
Valve is a self-funded entertainment content-producing company that focuses on providing an incredibly unique and dynamic work environment for its employees. It operates with fluid roles and places emphasis on continually improving and innovating, while always prioritizing the best interests of its customers and employees. The company owns all of its intellectual property and has never brought in outside financing since its early days, giving it the freedom to shape the company and its business practices according to its own vision.
******************************************
It works! With this we will be able to prompt our LLM and search for relevant context within our collections to aid the model in generating higher quality responses to our questions.
4. Conclusion
In this notebook we have explored running an LLM locally, and creating a vector database for our documents that will be used in RAG to generate higher quality responses. This combines the power of a simple similarity search for relevant documentation with the capabilities of an LLM that can rephrase parts of our documents into a more digestable format.